🎍목표🎍
-기계 학습의 개념에 대해 살펴본다
-선형 회귀 문제를 sklearn 라이브러리를 이용하여 실습해본다
-XOR 문제를 케라스 라이브러리를 이용하여 실습해본다
-숫자 인식 프로그램을 케라스 라이브러리를 이용하여 실습해본다
16.1 이번 장에서 만들 프로그램
기계 학습 분야(인공지능)는 최근 가장 각광을 받는 분야
기계 학습 개념을 살펴보고, 케라스 라이브러리를 이용하여 간단한 기계 학습 프로그램 작성해보기
(1) 선형 회귀 분석 프로그램을 sklearn 라이브러리를 이용하여 작성해보자

(2) 필기체 숫자 인식 프로그램을 케라스 라이브러리를 이용하여 작성해보자

16.2 기계 학습
컴퓨터가 사람처럼 스스로 배울 수 있다면 어떤 세상이 올까?
기계 학습(Machine Learning): 인공지능의 한 분야로 컴퓨터에 학습 기능을 부여하기 위한 연구 분야
"기계 학습"이란 용어는 1959년 아서 사무엘(Arthur Samuel)에 의해 만들어졌다.
패턴 인식 및 계산 학습 이론에서 진화한 기계 학습은 컴퓨터가 주어진 데이터를 학습하는 알고리즘을 연구한다. 학습할 수 있는 데이터가 많아지면 알고리즘 성능이 향상된다. 이들 알고리즘은 항상 고정적인 의사 결정을 하는 프로그램과는 다르게 데이터 중심의 예측 또는 결정을 내릴 수 있다. 기계 학습은 어떤 문제에 대하여 명시적 알고리즘을 설계하고 프로그래밍 하는 것이 어렵거나 불가능한 경우에 주로 사용된다.
ex) 스팸 이메일 필터링, 네트워크 침입자 작동 검출, 광학 문자 인식(OCR), 컴퓨터 비전 등
기계 학습이 중요하게 사용되는 분야
기계 학습은 빅데이터와 아주 밀접한 관계가 있다. 학습을 시키려면 많은 데이터가 필수적이기 때문이다.
기계 학습은 문제를 해결하는데 많은 경우가 있어서 각각의 경우를 정화하게 처리하는 것이 불가능한 경우에 필요하다.
ex) 바둑 탐색, 스팸 이메일 필터링, 자율 주행 자동차
복잡한 데이터들이 있고 이들 데이터에 기반하여 결정을 내려야 하는 경우, 기계 학습을 이용하면 정확하고도 빠른 결정을 내릴 수 있다. 기계 학습이 많이 사용되는 분야는 다음과 같다.
-음성 인식처럼 프로그램으로 작성하기에는 규칙과 공식이 너무 복잡할 때 (인간도 잘 몰르는 분야)
-신용 카드 거래 기록에서 사기 탐지 - 작업 규칙이 지속적으로 바뀌는 상황
-주식 거래나 에너지 수요 예측, 쇼핑 추세 예측처럼 데이터 특징이 계속 바뀌고 프로그램을 계속해서 변경해야 하는 상황
-스팸메일 판단
-구매자가 클릭할 확률이 가장 높은 광고가 무엇인지 알아내고 싶을 때, 사용자가 선호하는 상품이나 비디오를 자동으로 추천하고 싶을 때
-영상 인식: 얼굴 인식, 움직임 감지, 개체 감지, 자율 주행에 나타나는 다양한 상황을 처리하고 싶을 때, 이미지 자동 분류, 이미지 데이터베이스 중에서 특정 이미지를 탐색하고 싶을 때
16.3 기계 학습의 분류
기계 학습은 일반적으로 학습을 지도해주는 "교사"의 유무에 다라 크게 지도 학습과 비지도 학습으로 나어진다.
🐚지도 학습(Supervised Learning): 컴퓨터는 "교사"에 의해 주어진 예제와 정답(레이블)을 제공 받는다.
-지도 학습의 목표: 입려을 출려에 매핑하는 일반적인 규칙을 학습하는 것
ex) 예제 영상 주고 이후에 컴퓨터가 고양이인지 강아지인지 구별
🐚비지도 학습(Unsupervised Learning): 외부에서 정답(레이블)이 주어지지 않고 학습 알고리즘이 스스로 입력에서 어떠한 구조를 발견하는 학습
->데이터에서 숨겨진 패턴 발견 가능
ex) 클러스터링(clustering) - 구글 뉴스에서 비슷한 뉴스를 자동으로 그룹핑하는 것
🐚강화 학습(Reinforcement Learning): 보상이나 처벌 형태의 피드백으로 학습이 이루어지는 기계 학습
주로 차량 운전이나 상대방과의 경기 같은 동적인 환경에서 프로그램의 행동에 대한 피드백만 제공됨
ex) 바둑에서 어떤 수를 두어서 승리했다면 보상이 주어지는 방식
지도학습
지도 학습: 입력-출력 쌍을 학습한 후에 새로운 입력값이 들어왔을 때 출력값을 합리적으로 예측하는 것
즉, 지도 학습은 입력(x)과 출력(y)이 주어질 때 입력에서 출력으로의 매핑 함수를 학습하는 것
y=f(x)
학습이 종료된 후에 새로운 입력 데이터(x)에 대하여 매핑 함수를 이용하여 출력값(y)을 예측한다.
ex) 컴퓨터에게 직선의 방정식 y=10x 위의 점들을 입력하고 (1, 10), (2, 20) 학습이 끝난 후에 x=5를 입력하면 컴퓨터가 y=50이라는 답을 할 수 있도록 만드는 것
지도 학습은 크게 선형 회귀와 분류로 나눌 수 있다.
지도 학습: 회귀(regression)
회귀(regression): 일반적으로 예제 데이터들을 2차언 공간에 찍은 후에 이들 데이터들을 가장 잘 설명하는 직선이나 곡선을 찾는 문제
학습이 끝난 후에 새로운 데이터가 들어오면 이 직선이나 곡선을 이용하여 출력 값을 예측하게 된다.

회귀에서는 출력(y)의 형태가 이산적이 아니라 연속적이다. 즉 y=f(x)에서 입력 x와 출력 y가 모두 실수이다.회귀에서는 입력과 출력을 보면서 함수 f(x)를 예측하게 된다. 예를들어 출력이 "달러"이거나 "무게"와 같은 실수이다.
회귀 기법은 주식의 추세선을 예측하거나 흡연과 사망률 사이의 관계, 온도 변화나 전력 수요 변동 등의 연속적인 응답을 예측하는데 사용된다. 아래 그림과 같이 선형 회귀도 있고 비선형 회귀도 있다.

전통적인 선형 회귀(linear regression)는 직선만을 사용하는 회귀 방법
선형 회귀는 "기계학습"으로 생각하기에는 너무 단순하고 "통계"적 방법이라고 생각하는 사람들도 있다. 하지만 회귀 문제도 y=f(x)에서 입력(x)에 대응되는 실수(y)들이 주어지고 함수 f(x)를 학습하는 것이므로 일종의 기계 학습 문제로 생각할 수 있다.
회귀는 데이터를 가장 잘 설명하는 직선을 찾은 후에 새로운 입려깅 들어오면 직선을 이용하여 새로운 출력을 예측한다.
지도학습: 분류(classification)
식 y=f(x)에서 출력 y가 이산적(discrete)인 경우에 이것을 분류 문제(또는 인식 문제)라고 부른다. 분류는 입력을 2개 이상의 클래스로 나눈다. 분류 문제는 우리가 일상에서 가장 많이 접하는 문제 중의 하나이다.
ex) 사진을 보고 강아지 또는 고양이로 분류하기, 스팸 메일 분류, 종양이 악성인지 양성인지 판단, 음성 인식이나 영상 인식
분류는 지도 학습의 형태로 이루어지는 것이 일반적
교사가 만들어 놓은 학습 데이터를 가지고 컴퓨터가 지도 학습을 수행
이후에 새로운 데이터가 컴퓨터에 주어지고 컴퓨터는 학습을 바탕으로 분류 수행
분류를 수행하기 위한 일반적인 알고리즘에는 신경망(딥러닝), kNN(k-nearest neighbor), SVM(Support Vector Machine), 의사 결정 트리 등이 있다.
비지도 학습
비지도 학습(unsupervised learning): "교사"없이 컴퓨터가 스스로 입력들을 분류하는 것
식 y=f(x)에서 정답인 레이블 y가 주어지지 않는 것
비지도 학습은 정답이 없는 문제를 푸는 것과 같으므로 학습이 맞게 되었는지 확인할 수는 없다. 하지만 데이터들의 상관도를 분석하여 유사한 데이터들을 모을 수는 있다.
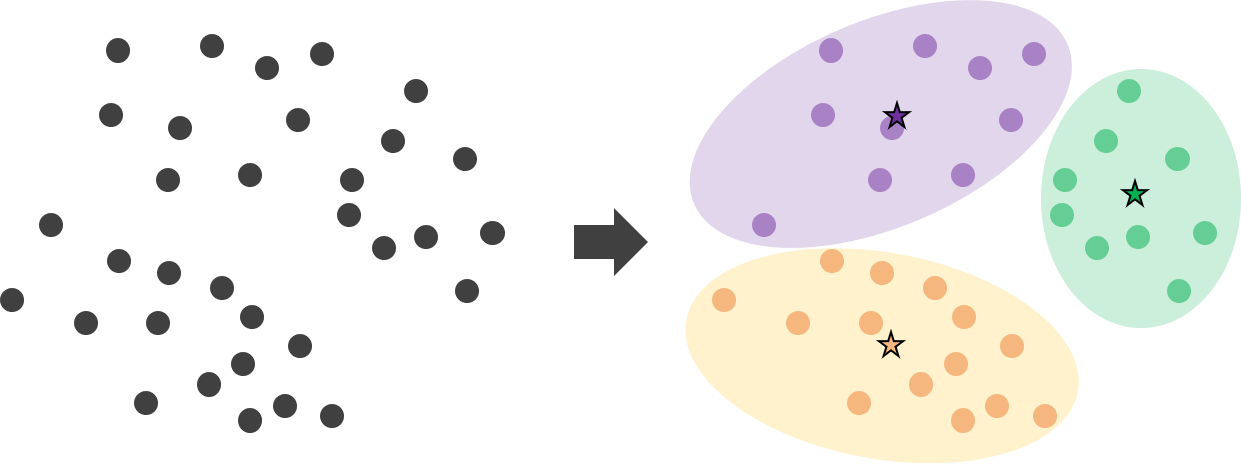
-가장 대표적인 비지도 학습: 클러스터링(군집화, clustering)
클러스터링이란 입력 데이터 간의 거리를 계산해서 입력을 몇 개의 군집으로 나누는 방법
K-means 클러스터링이 가장 고전적인 클러스터링 방법 (k평균 알고리즘)
16.4 기계 학습의 요소들
특징(feature)
데이터를 학습시킬 때 데이터를 원형 그대로 사용하기도 하지만 일반적으로는 데이터에서 특징을 추출하여 이것을 학습시키고 테스트하게 된다.
특징: 우리가 학습 모델에게 공급하는 입력
가장 간단한 경우에는 입력 자체가 특징이 된다.
ex) 월급 결정할 때 성과만 고려한다면 성과가 바로 특지잉 된다.
스팸메일을 분류할 때 원천 데이터는 이메일의 발신자 주소 등
하지만 이것은 그대로 학습시키기에 너무 복잡함
-이메일에 "검찰"이라는 단어 포함 여부 (yes or no)
-이메일에 "광고", "선물 교환권"이나 "이벤트 다첨" 단어 포함 여부
-이메일 발신자의 도메인(문자열)
-이메일의 제목이나 본문에 있는 ★과 같은 특수 기호의 개수 (정수)
-이미지로만 이뤄진 메일
-임베디드 코드가 삽입된 이메일
학습 데이터와 테스트 데이터
색상과 곡률을 특징으로 사용해서 입력을 "원"과 "사각형"으로 분류하는 기계 학습 시스템을 생각하자.
"원"과 "사각형" 레이블이 붙어 있는 학습 데이터로 시스템을 학습시킨다.
학습 알고리즘은 입력 데이터의 특징에 따라 입력을 "원"과 "사각형"으로 분류할 수 있는 모델을 내부적으로 생성한다.
학습이 끝나면 한 번도 본 적이 없는 새로운 데이터로 시스템을 테스트한다.
ex)알파고도 예전에 받구 고수들이 두었던 수많은 기보를 입수해서 데이터로 사ㅛㅇ해 시스템을 학습시켰다. 학습이 끝나면 알파고는 새로운 수에 대해서도 대응할 수 있다.
16.5 선형 회귀 분석
파이썬에서 가장 많이 사용되는 기계 학습 라이브러리 중 하나인 sklearn을 사용하여 선혀 회귀 분석을 구현해보자
선형 회귀 분석
직선의 방정식: f(x) = mx+b
여기서 m은 기울기, b는 절편
기본적으로 선형 회귀는 입력 데이터를 가장 잘 설명하는 직선의 기울기와 절편을 찾는 문제
직선에서 우리가 제어할 수 있는 값은 기울기(m)와 절편(b)이다. 기계 학습에서는 기울기 대신에 가중치(weight)라는 용어를 많이 사용한다. 마찬가지로 절편 대신에 바이어스(bias)라고 한다. 따라서 다음과 같은 식으로 변경하자.
f(x) = Wx+b
가중치와 바이어스의 값에 따라 여러 개의 직선이 있을 수 있다. 기본적으로 선형 회귀 알고리즘은 데이터 요소에 여러 직선을 맞췅 본 후 가장 적은 오류를 발생시키는 직선을 찾는다.
하나의 예제로 키와 몸무게 사이에는 어떤 관계가 있는지 알아보자. 키와 몸무게를 나타내는 학습 데이터를 가지고 지도 학습을 시켜보자.
| 키(단위: cm) | 몸무게(단위: kg) |
| 174 | 71 |
| 152 | 55 |
| 138 | 46 |
| 128 | 38 |
| 186 | 88 |
키(x)=178이면 몸무게는? => 선형 회귀 모델 => 몸무게(y)=77로 예측됩니다
위의 표에 들어 있는 데이터를 이용해 선형 회귀 시스템을 학습시킨 후에 새로운 키를 넣었을 때 몸무게를 예측할 수 있는 시스템을 만들고자 한다.
제일 먼저 해야할 것은 sklearn 라이브러리에서 linear_model 모듈을 가져오는 작업이다. 이어서 linear_model에 포함되어 있는 LinearRegression() 생성자를 호출한다.
import matplotlib.pyplot as plt
from sklearn import linear_model
reg = linear_model.LinearRegression() #선형 회귀 객체 생성학습 데이터는 반드시 2차원 배열이어야 한다. 2차원 배열에서 하나의 행은 하나의 예제를 나타낸다. 열은 입력의 특징을 나타낸다. 따라서 입력 특징이 많으면 열의 개수가 증가한다. 우리는 파이썬 리스트의 리스트를 만들어서 다음과 같은 2차원 배열을 생성한다. 학습 데이터에 한 열만 있어도 반드시 2차원 배열 형태로 만들어야 한다. 레이블은 1차원 배열이면 된다.
# 샘플 번호 컬럼 #1

X = [[174], [152], [138], [128], [186]] #학습 예제
y = [71, 55, 46, 38, 88] #정답
reg.fit(X, y)
학습시키려면 fit()함수를 호출하고 X와 y를 전달한다. 학습이 종료되면 발견된 직선의 기울기와 절편을 알 수 있다.
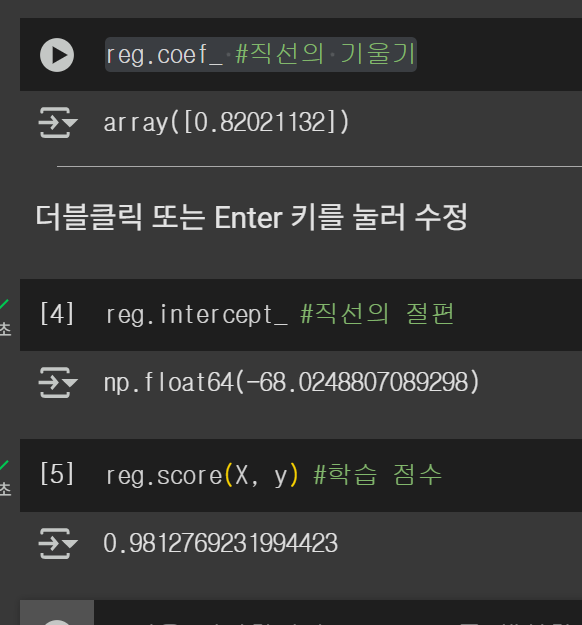
score() 함수는 회귀 분석이 얼마나 잘 데이터에 맞추었는지를 반홚나다. 어느 저도 선형 데이터를 사용했으므로 1.0에 가까울 것이다.
이제 학습이 완료되었으므로 새로운 값 178을 넣어서 몸무게를 얼마로 예측하는지를 살펴보자. 즉 키가 178일 때 몸무게를 예측해보는 것이다. 예측 시에는 predict() 함수를 사용한다.
reg.predict([[178]])>>>
array([77.97273347])
몸무게는 77kg로 예측되었다. 이제 우리가 찾은 직선을 그래프로 그려보자.
#학습 데이터를 산포도로 그린다.
plt.scatter(X, y, color='black')
#학습 데이터를 입력으로 하여 예측값을 계산한다. 직선을 가지고 예측하기 때문에 직선상의 점이 된다.
y_pred = reg.predict(X)
#예측 값으로 선 그래프를 그린다.
#직선이 그려진다.
plt.plot(X, y_pred, color='blue', linewidth=3)
plt.show()
plt.show()
검정색 점으로 그려진 것이 학습 데이터이다. 선형 회귀로 찾은 직선은 파랑색으로 그려져 있다.
LAB: 선형 회귀 실습
import matplotlib.pylab as plt
from sklearn import linear_model
reg = linear_model.LinearRegression() #선형 회귀 객체 생성
X = [[1.0], [2.0], [3.0], [4.0], [5.0]]
y = [1.0, 2.0, 1.6, 3.8, 2.3]
reg.fit(X, y) #학습
#학습 데이터와 y값을 산포도로 그린다.
plt.scatter(X, y, color='black')
#학습 데이터를 입력으로 하여 예측 값을 계산한다.
y_pred = reg.predict(X)
#학습 데이터와 예측값을 선 그래프로 그린다.
#계산된 기울기와 y 절편을 가지는 직선이 그려진다.
plt.plot(X, y_pred, color='blue', linewidth=3)
plt.show()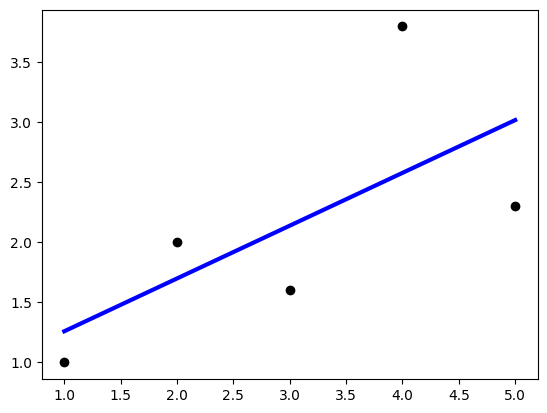
16.6 신경망
최근에 많은 인기를 끌고 있는 딥러닝(Deep Learning)의 시작은 1950년대부터 연구되어 온 인공 신경망(artificial neural network: ANN)이다. 인공신경망은 생물학적인 신경망엥서 영감을 받아서 만들어진 컴퓨팅구조이다.
인간의 두뇌는 뉴런으로 이루어져 있다. 뉴런은 수상돌기(dendrite)를 토하여 주위의 뉴런들로부터 신경 자극을 받아서 세포체(cell body)에서 어떤 처리를 한 후에 축삭 돌기(axon)을 통하여 다른 세포들로부터 출력을 내보낸다.
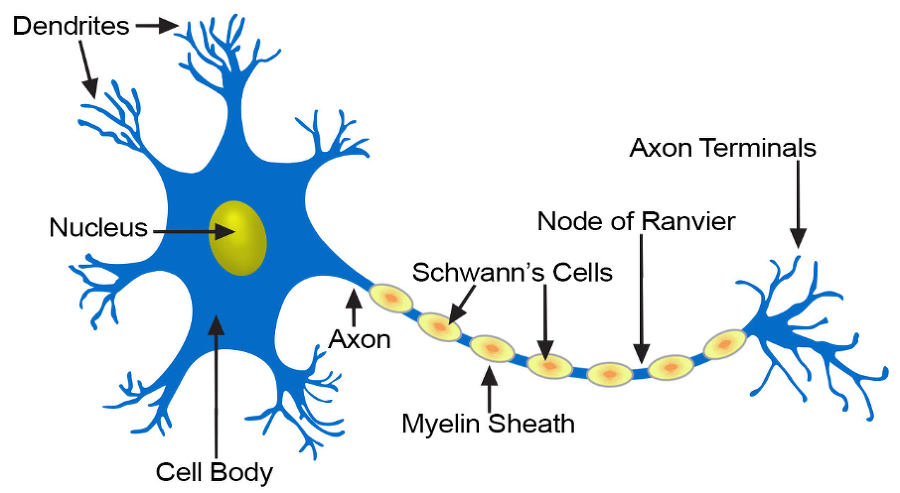
하나의 뉴런은 아주 단순한 계산만을 하고 속도는 느리지만, 수백만 개를 모아 놓으면 아주 복잡한 작업을 수행할 수 있다. 현재 우리가 사용하고 있는 컴퓨터는 하나의 강력한 CPU로 되어 있지만, 인공신경망은 이와는 다르게, 간단한 CPU들을 엄청나게 많이 사용해서 복잡한 작업을 하려는 시도이다. 인공신경망의 뉴런들은 병렬로 동작하고 일부가 손상되어도 전체 기능에는 큰 이상이 없다.
구체적으로 입력층과 출력층 사이에 은닉층(hidden layer)을 가지고 있는 신경망을 생각할 수 있다.
이 구조를 다층 퍼셉트론(multilayer perceptron: MLP)이라고 부른다.
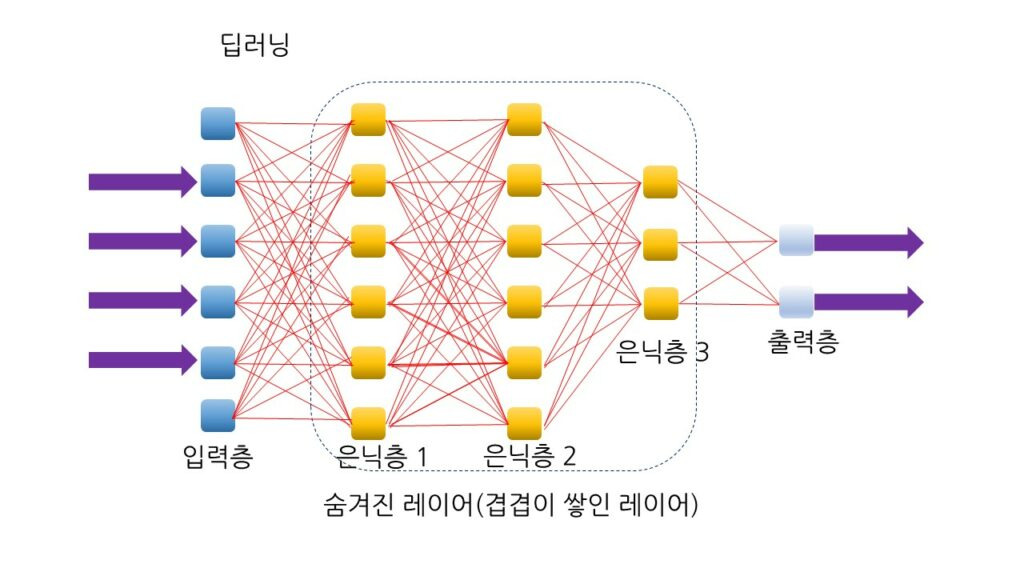
1970년대와 1980년대에는 여러 분야에서 도시적으로 다층 퍼셉트론에 사용할 수 있는 학습 알고리즘이 발견되었다. 이 학습 알고리즘을 역전파 알고리즘(back-propagation)이라고 한다. 이 알고리즘으로 인하여 1980년대에 다시 신경망에 대한 관심이 살아났다. 이 알고리즘이 지금까지도 신경망 학습 알고리즘의 근간이 되고 있다.
딥러닝
딥러닝: DNN(Deep Neural Networks)에서 사용하는 학습 알고리즘
DNN은 MLP(다층 퍼셉트론)에서 은닉층의 개수를 증가시킨 것
은닉층을 하나만 사용하는 것이 아니고 여러 개를 사용한다.
"딥(deep)"이라는 용어가 은닉츠이 깊다는 것을 의미함
최근 딥러닝은 컴퓨터 시각, 음성 인식, 자연어 처리, 소셜 네트워크 필터링, 기계 번역 등에 적용되어서 인간 전문가에 필적하는 결과를 얻고 있다.
뉴런의 모델
신경망에서는 하나의 뉴런을 다음과 같이 모델링한다.
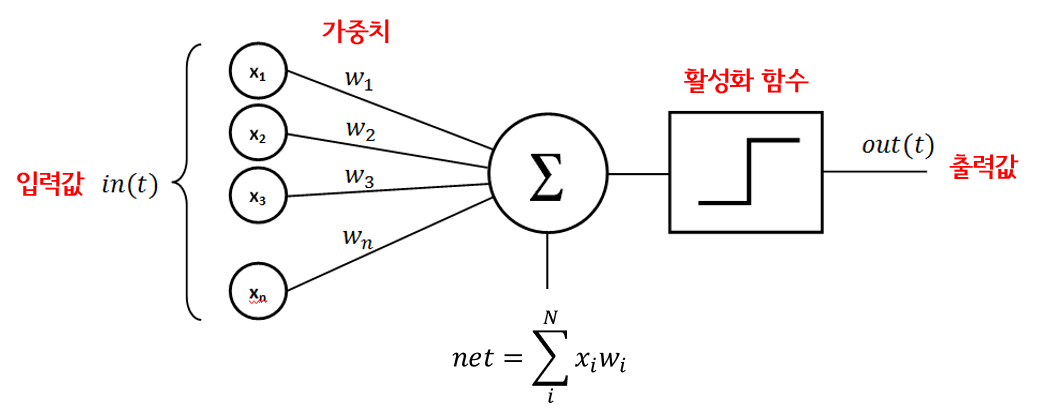

x1, x2는 입력 신호고 w1, w2는 가중치(weight)이다. b는 바이어스(bias)라고 불리는 임계값이다. 시그마 뒤의 식이 계산되고 이것이 활성화 함수로 입력된다. 활성화 함수(activation function)는 입력갑싀 가중 합계값을 받아서 출력 값을 계산하는 함수이다. 일반적으로 사용되는 활성화 함수들은 다음과 같다.

활성화 함수는 미분 가능하고 연속적이어야 한다. 학습 알고리즘에서 활성화 함수의 일차 미분값을 사용하기 때문이다. 최근 가장 인기 많은 활성화 함수는 ReLU이다.
역전파 학습 알고리즘
역전파 알고리즘은 입력이 주어지면 순방향으로 계산하여 출력을 계산한 후에 실제 출력과 우리가 원하는 출력 간의 오차를 계산한다. 이 오차를 역방향으로 전파하면서 오차를 줄이는 방향으로 가중치를 변경한다.

MLP에서 학습을 시킬 때는 실제 출력과 원하는 출력 사이의 오차를 이용한다. 오차를 줄이는 방향으로 가중치를 변경하는 것이다. 이것을 위하여 오차를 계산하는 함수를 손실 함수(loss function)이라고 한다.
손실 함수란 무엇인가?
MLP를 학습시킬 때는 많은 샘플(사례)를 보여주면서 실제 출력과 목표 출력의 차이를 계산할 수 있다. 이 차이를 오차로 사용할 수 있다. 예를 들어서 사진을 보고 강아지와 고양이를 구별하는 신경망을 생각해보자. 출력 노드는 두 개다. 강아지 사진이 주어지면 출력 노드는 (1,0)이어야 한다. 고양이 사진이라면 출력 노드는 (0, 1)이어야 한다.

예를 들어서 1000장의 사진을 가지고 학습을 수행한다고 하자. 고양이 사진을 보여주었는데 출력이 (1, 0)이 나왔다면 올바르게 분류한 것이고 오차는 0이다. 이어서 강아지 사진을 보여줬는데 (1, 0)으로 분류한다면 잘못 분류한 것이다. (0, 1)로 나와야 하는데 (1, 0)으로 나온 것이므로 오차는 (0-1)**2 + (1-0)**2=2.0이 될 것이다.
우리는 손실 함수(loss function)를 다음과 같이 정의할 수 있다.

E는 E(w)라 하자.
여기서 w는 가주치이고, k는 출력 노드의 번호이다. 훈련 예제의 목표 출력 값이 yk이다. 실제로 출력되는 값은 tk이다. 전체 오차는 목표 출력 값에서 실제 출력값을 빼서 제곱한 값을 모든 출력 노드ㅔㅇ 대하여 합한 갑시다. 우리는 손실 함수 E(w)를 최소로 만드는 가중치 w를 찾으면 된다.
역전파 알고리즘은 손실 함수 값을 줄이는 문제를 최적화 문제(optimization)로 접근한다. 최적화 문제란 어떤 함수를 최소로 만들거나 최대로 만드는 값을 찾는 문제이다. 우리는 여기서 이 손실 함수 값을 최소로 하는 가중치를 찾으면 된다. 만약 손실 함수 값이 0이 되었다면 신경망이 입력을 완벽하게 분류한 것이다. 학스빙란 손실 함수를 최소로 만드는 가중치를 찾는 작업이다.
오차값을 최소화하는 가중치를 찾는 데 일반적으로 사용되는 알고리즘 중의 하나가 경사 하강법(gradient descent)이다. 경사 하강법은 함수의 최소값을 찾기 위한 1차 미분(그래디언트)을 사용하는 반복적인 최적화 알고리즘이다. 현재 위치에서 함수의 그래디언트값을 계산한 후에 그래디언트의 반대 방향으로 움직이는 방법이다. 우리는 손실 함수의 최소값을 찾기 위해 경사 하강법을 사용할 것이다.

*그래디언트는 접선의 기울기로 이해해도 된다. 접선의 기울기가 양수이면 반대로 w를 감소시킨다.
어떤 위치에서의 그래디언트는 w를 조금 증가했을 때 손실 함수가 얼마나 증가하는가를 나타낸다(그래디언트는 1차 미분값이고 미분의 정의에 의해서). 예를 들어서 현재 위치에서 그래디언트가 10이 나왔다면 w를 조금 증가했을 때 손실 함수는 10만큼 증가한다는 것을 나타낸다. 이때는 우리는 w를 감소시켜야 손실 함수가 감소할 것이다. 만약 그래디언트가 -10이 나왔다면 w를 조금 증가시켰을 때 손실함수가 감소한다는 ㅢ미이므로 우리는 w를 증가시켜야 한다. 즉 우리는 그래디언트의 반대 방향으로 가면 된다.
LAB: 활성화 함수 실험
https://playground.tensorflow.org
접속하면 구글이 제공하는 신경망 시뮬레이터 이용 가능

16.7 케라스(Keras)
텐서플로우 위에서 고수준 라이브러리인 케라스를 사용해보자.
케라스는 파이썬으로 작성되었으며 텐서플로우에서 실행할 수 있는 고수준 딥러닝 API이다. 케라스는 빠른 실험을 가능하게 하는 데 중점을 두고 개발되었다. 케라스의 특징은 다음과 같다.

-쉽고 빠른 프로토타이핑이 가능하다.
-순방향 신경망, 컨볼루션 신경망과 반복적인 신경망은 물론 여러 가지의 조합도 지원한다.
-CPU 및 GPU에서 원활하게 실행된다.

케라스의 핵심 데이터 구조는 모델(model)이며 이것은 레이어를 구성하는 방법을 나타낸다. 가장 간단한 모델 유형은 Sequential 선형 스택 모델(순바향으로 전파되는 신경망 모델)이다. 케라스를 사용하면 신경망을 레고 조립하듯이 만들 수 있다.
Sequential 모델을 생성하려면 다음과 같은 문장을 사용한다.
import tensorflow as tf
import numpy as np
model = tf.keras.Sequential()
모델에 레이어를 쌓으려면 add() 함수를 사용한다.
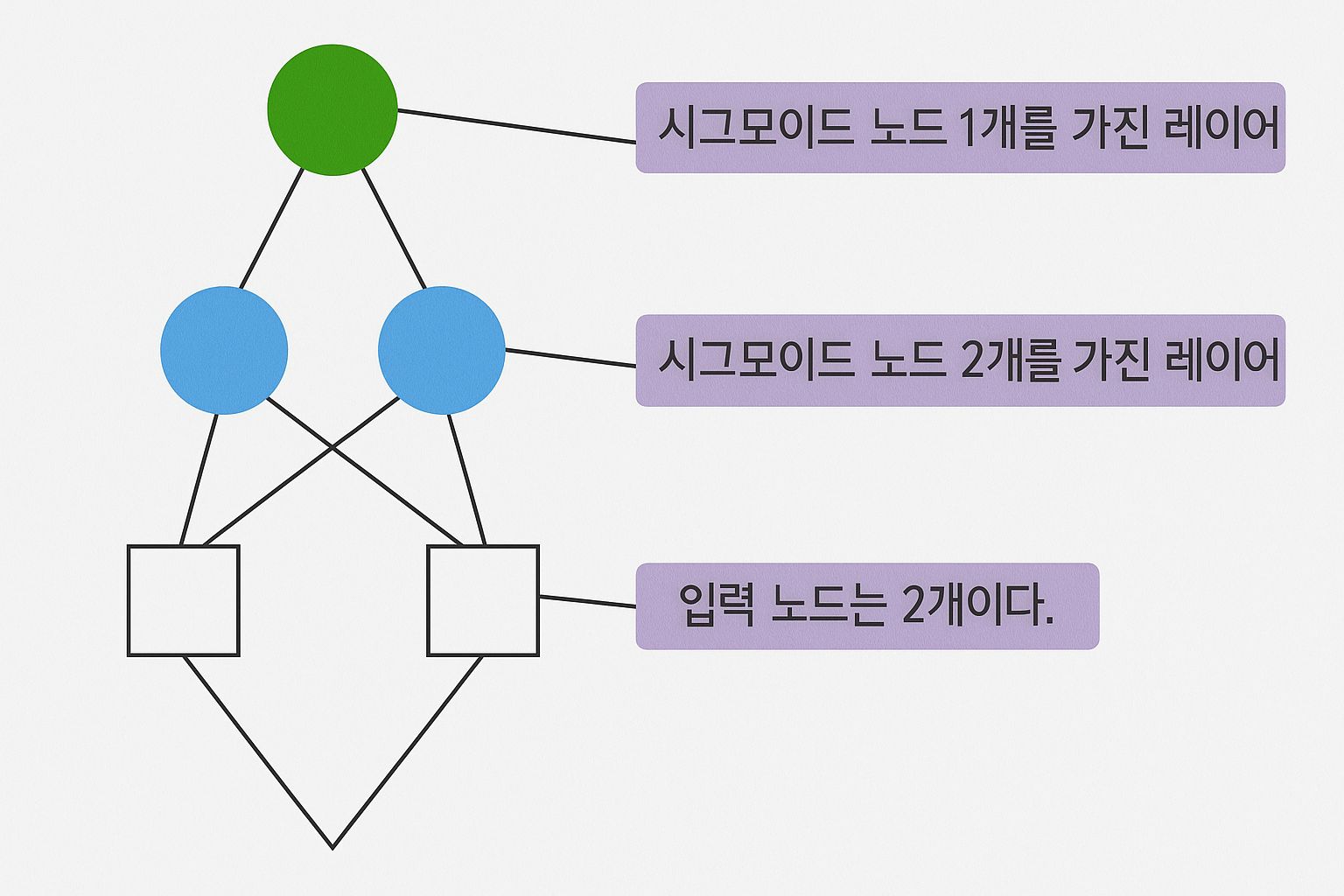
model.add(tf.keras.layers.Dense(units=2, input_dim=2, activation='sigmoid')) #①
model.add(tf.keras.layers.Dense(units=1, activation='sigmoid')) #②Dense 클래스는 완전 연결된 레이어를 구현하는 클래스이다. 하단의 레이어와 완전히 연결되어 있다는 의미이다. ①에서 units 매개변수는 노드의 개수이다. input_dim은 입력의 개수이다. activation은 활성화 함수이다. 시그모이드 활성화 함수를 사용한다. ②에서 노드의 개수가 1인 완전 연결된 레이어를 추가한다. 활성화 함수는 역시 시그모이드이다.
우리는 최적화 방법으로 경사 하강법을 사용한다. 아래 문장에서 경사 하강법을 나타내는 객체를 생성한다.
sgd = tf.keras.optimizers.SGD(learning_rate=0.1)위의 문장에서는 학습률(learning_rate)을 0.1로 지정하였다. 학습률은 한 번의 학습에서 가중치가 변경되는 비율이다.
케라스의 모델이 완성되면 compile() 함수를 이용하여 학습 과정을 구성한다.
model.compile(loss='mean_squared_error', optimizer=sgd)매개변수 loss는 손실 함수를 지정한다. 현재는 평균 제곱 오차(mean_squared_error)로 설정되어 있다. 평균 제곱 오차는 실제 출력과 목표 출력 사이의 오차를 계산하여 제곱한 후에 모든 출력 노드에 대하여 평균을 낸 값이다.
케라스 모델이 만들어지면 학습을 진행할 수 있다. 학습은 fit() 함수를 호출하면 된다. 우리는 논리적인 XOR를 학습시킬 것이다. 즉 다음과 같은 입력값과 출력값을 사용하여 학습한다. 이 문제는 아주 유명한 문제이다. 이것이 학습이 안되어서 1950년대에 잘 나가던 신경망 연구가 전부 중지되었다.

X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
model.fit(X, y, batch_size=1, epochs=10000)
여기서 X와 y는 넘파이 배열이다. X에는 입력 데이터가 들어 있고 y에는 목표 출력이 저장되어 있다. epochs는 전체 샘플을 반복하는 횟수이다. batch_size를 1로 설정하는 것은 1 샘플 마다 가중치가 변경된다는 것을 의미한다.
예측값은 다음과 같이 predict()으로 테스트 할 수 있다.
XOR과 아주 똑같지는 않지만, 상당히 유사한 값이 나오는 것을 볼 수 있다. XOR는 상당히 학습시키기 어려운 문제로 알려져 있다.
print(model.predict(X))*학습률
신경망에서 학습률(learning rate)이란 한 번 학습시킬 때 뉴런의 가중치를 변경하는 비율이다. 학습을 진행할 때 가중치를 한 번에 크게 변경하는 것이 아니라 조금씩 여러 번 하게 된다. 학습률이 높으면 학습이 빨리 되지만, 발산이 발생할 수도 있다. 따라서 적절한 학습률을 찾아야 한다.
LAB: 논리적인 OR학습

import tensorflow as tf
import numpy as np
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(units=2, input_dim=2, activation='sigmoid'))
model.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))
sgd = tf.keras.optimizers.SGD(learning_rate=0.1)
model.compile(loss='mean_squared_error', optimizer=sgd)
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([[0], [1], [1], [1]])
model.fit(X, y, batch_size=1, epochs=1000)
print(model.predict(X))

16.8 케라스를 이용한 MNIST 숫자 인식
케라스를 이용해 필기체 숫자 이미지를 인식하는 MLP 신경망을 작성해보자. 미국의 표준 연구소가 만들어서 배포하는 MNIST는 필기체 숫자 이미지를 모아둔 데이터 세트이다. 케라스에는 MNIST 데이터 세트가 포함되어 있다.
->55,000개의 학습 이미지 / 10,000개의 테스트 이미지
다음과 같은 구조의 MLP를 구성해보자. 입력은 필기체 숫자 이미지이다. 출력은 10개의 노드로서 숫자 0부터 9까지를 나타낸다. 즉 숫자 0의 이미지가 신경망에 입력되면 첫 번째 출력의 노드 값이 1.0이 되고 나머지 출력 노드들의 값은 0.0이 되어야 한다.
우리는 2차원의 이미지를 받아서 1차원으로 변환한 후에 신경망에 입력한다. 2차원 이미지는 28X28이고 이것을 1차원으로 변경하면 784X1이 된다.
숫자 데이터 가져오기
케라스가 기본적으로 제공하는 MNIST 데이터에서 숫자이미지들을 가져온 후 훈련 데이터와 테스트 데이터로 나누어 보자.
import matplotlib.pyplot as plt
import tensorflow as tf
mnist = tf.keras.datasets.mnist
#훈련 데이터와 테스트 데이터를 가져온다.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#넘파이를 사용하여 입력을 0.0에서 1.0 사이로 만든다.
x_train, x_test = x_train / 255.0, x_test / 255.0load_data()는 훈련 데이터와 테스트 데이터를 반환한다. 이들을 넘파이 배열인 x_train, y_train, x_test, y_test에 저장한다. 또 0에서 255사이의 값을 가지는 픽셀 값들을 0.0에서 1.0 사이의 실수값으로 변환한다. 신경망의 입력은 0.0에서 1.0 사이의 값으로 정규화 되어야 한다.

입력 이미지는 다음과 같이 출력해볼 수 있다.
plt.imshow(x_train[0], cmap='Greys')
모델 구축하기
케라스 모델은 레고처럼 레이어를 쌓아서 만들어진다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(512, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
Flatten 레이어는 입력을 28x28에서 784X1로 만든다. Dense 레이어는 전체의 뉴런이 연결된 밀집 레이어를 모델에 추가한다. 이때 활성화 함수는 ReLU로 지정한다. Dropout 레이어는 드롭아웃을 위한 레이어다. 드롭아웃은 몇 개의 뉴런을 학습에서 제외하여 과잉적합을 회피하는 기법이다. 현재 0.2 비율의 뉴런을 학습에서 제외한다. 또 출력을 위한 Dense 레이어를 추가한다. 이때 활섷와 함수는 소프트맥스로 지정하고 있다. 소프트맥스는 출력 노드 주 에서 하나만 1로 만들고 나머지는 0으로 만드는 활성화 함수이다.
학습시키기
모데링 완성되면 학습을 위해 옵티마이저와 손실 함수, 지표 등을 정의한다.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])현재 옵티마이저는 'adam'으로 지정되었다. ICLR 2015 학술대회에서 처음으로 발표된 'adam'은 학습 도중에 학습률을 적응적으로 변경시키는 최적화 알고리즘이다. 손실 함수는 'sparse_categorical_crossentropy'로 지정되었다. 이것은 교차 엔트로피 값을 손실 함수로 지정한다. 교차 엔트로피는 출력 노드 가운데 하나만을 1.0으로 만들기 위해 사용하는 손실함수이다.
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)모델이 완성되었으므로 학습시키고 학습이 끝나면 평가해보자.
Epoch 1/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 16s 8ms/step - accuracy: 0.8949 - loss: 0.3625
Epoch 2/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 13s 7ms/step - accuracy: 0.9700 - loss: 0.0993
Epoch 3/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 21s 7ms/step - accuracy: 0.9789 - loss: 0.0676
Epoch 4/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 13s 7ms/step - accuracy: 0.9840 - loss: 0.0485
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 13s 7ms/step - accuracy: 0.9868 - loss: 0.0397
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - accuracy: 0.9734 - loss: 0.0917
[0.07593149691820145, 0.9769999980926514]
*드롭아웃
드롭아웃은 과적합(overfitting) 문제를 해결하기 위한 방법 주 하나로 학습시 전체 신경망 중 일부만을 사용하도록 하는 것이다. 매 학습마다 랜덤으로 일부 뉴런을 상용하지 않음으로써 가중치들이 골고루 학습되도록 하는 기법이다.
LAB: Keras 실습
https://transcranial.github.io/keras-js/#/mnist-cnn
Keras.js - Run Keras models in the browser
transcranial.github.io
아주 좋은 시뮬레이션 사이트
우리가 코드를 작성해본 MNIST 숫자 인식부터 각종 이미지들을 인식할 수 있는 DNN 모델들이 Keras.js로 구현되어 있다.
16.9 타이타닉 생존자 예측하기
이 책에서 배운 모든 내용을 총정리해보자. 우리는 타이타닉 생존자를 예측하여 볼 것이다.
라이브러리 적재
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
학습 데이터 다운로드
train = pd.read_csv("train.csv", sep=',')
test = pd.read_csv("test.csv", sep=',')
작업을 하기 전에는 항상 데이터가 어떻게 생겼는지 보는 것이 바람직하다.
train.head()
이제부터는 학습에 사용할 속성(특징)에 대해 생각해보자. 또 데이터 중에는 관측값이 없는 데이터도 있기 때무넹 이러한 데이터는 미리 제거해야 한다. 데이터가 결손치를 가지고 있는지를 보려면 판다스 함수 중에서 isnull()을 사용한다. isnull()은 컬럼 값이 하나라도 비어 있으면 해당 데이터를 반환한다. 이것을 sum()으로 처리해 개수를 세자.
train.isnull().sum()
시각화
학습하기 전에 각 속성에 대한 생존률을 시각화 해보는 것이 학습에 도움이 된다. seaborn을 사용하면 좀 더 쉽게 통계를 내어 시각화 할 수 있다. 영화에서 보면 구명보트에 여성을 먼저 태운 것을 볼 수 있다. 따라서 먼저 성별에 따른 생존률을 시각화해보자.
df = train.groupby('Sex')['Survived'].mean()
df.plot(kind='bar')
plt.show()
판다스의 groupby 함수를 이용해서 성별로 분류한 후에 생존률의 평균을 계산한다. 이후 "Survived" 컬럼만 남기고 나머지는 없앤다. 이것을 막대그래프로 그리면 된다.
마찬가지로 "Pclass"에 대해서도 생존률 그래프를 그려보면 상당한 인과관계가 있다는 것을 알 수 있다.
학습 데이터 정제
학습 데이터에서 우리가 원하는 특징만 남기고 필요 없는 컬럼들을 삭제해야 한다. 판다스의 drop() 함수를 사용한다.
train.drop(['SibSp', 'Parch', 'Ticket', 'Embarked', 'Name', \
'Cabin', 'PassengerId', 'Fare', 'Age'], inplace=True, axis=1)여기서 inplace는 원래 데이터 프레임을 변경하라는 의미이다. axis=1은 축번호 1번(즉 컬럼)을 삭제하라는 의미이다. 또 결손치가 있는 데이터 행도 삭제해야 한다.
train.dropna(inplace=True)이제 train을 출력해보면 3개의 컬럼("Survived", "Sex", "Pclass")만 남아 있는 것을 알 수 있다.
train.head()
또 하나의 중요한 문제가 있다. 우리는 성별을 숫자로 바꿔야 한다. 학습에서는 모든 거이 숫자로 바뀌어야 하기 때문이다. "male", "female"과 같은 기호는 컴퓨터가 학습할 수 없다. 다음과 같이 데이터 프레임의 모든 요소를 검사하여 "male"과 "female" 기호를 숫자 1과 0으로 바꾸자.
for ix in train.index:
if train.loc[ix, 'Sex']=="male":
train.loc[ix, 'Sex']==1
else:
train.loc[ix, 'Sex']==0이제 학습에 필요한 목표 출력을 만들어보자. 우리의 목표 출력은 생존률로서 train.Survived로 추출할 수 있고, 이것은 2차원 배열이어서 np.ravel()을 이용하여 1차원 배열로 만들어야 한다. 또 학습 데이터에서 생존률을 이제 삭제하자.
target = np.ravel(train.Survived)
train.drop(["Survived"], inplace=True, axis=1)
Keras 모델 만들기
여기에서 우리가 만드는 Keras 모델은 MNIST에서 사용했던 모델과 아주 유사하다. 우선 "Squential"모델이다. 즉 순차적인 신경망 모델이라는 의미이다. 신경망에는 출력이 다시 입력으로 연결되는 순환 신경망도 있다. 우리의 모델은 순환 신경망이 아니다.
우리의 경우 출력은 "생존", "생존하지 못함"으로 나오면 된다. 즉 이진분류 문제이다. 따라서 시그모이드(Sigmoid) 출력층을 사용하면 된다. 입력층과 출력층 사이에 2개의 은닉층을 두도록 하자. Relu 활성화 함수를 사용한다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(16, activation='relu', input_shape=(2,)))
model.add(tf.keras.layers.Dense(8, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))이제 모델을 컴파일 해보자. 우리는 이진 교차 엔트로피 손실 함수를 사용한다. 경사하강법으로는 'adam'방법을 사용한다. 평가 기준은 정확도이다.
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])이제 학습을 시켜보자.
model.fit(train, target, epochs=30, batch_size=1, verbose=1)학습 데이터에서는 약 78%의 정확도를 보여준다.
전체 소스
import numpy as np
import pandas as pd
import tensorflow as tf
#데이터세트를 읽어들인다
train = pd.read_csv("train.csv", sep=',')
test = pd.read_csv("test.csv", sep=',')
#필요없는 컬럼을 삭제한다.
train.drop(['SibSp', 'Parch', 'Ticket', 'Embarked', 'Name', \
'Cabin', 'PassengerId', 'Fare', 'Age'], inplace=True, axis=1)
#결손치가 있는 데이터 행은 삭제한다.
train.dropna(inplace=True)
#기호를 수치로 변환한다.
for ix in train.index:
if train.loc[ix, 'Sex']=="male":
train.loc[ix, 'Sex']=1
else:
train.loc[ix, 'Sex']=0
#2차원 배열을 1차원 배열로 평탄화한다.
target = np.ravel(train.Survived)
#생존 여부를 학습 데이터에서 삭제한다.
train.drop(['Survive'], inplace=True, axis=1)
#케라스 모델을 생성한다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(16, activation='relu', input_shape=(2,)))
model.add(tf.keras.layers.Dense(8, activation='relu'))
model.add(tf.keras.layer.Dense(1, activation='sigmoid'))
#케라스 모델을 컴파일 한다.
model.compile(los='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
#케라스 모델을 학습시킨다.
model.fit(train, target, epochs=30, batch_size=1, verbose=1)드디어 이 책이 끝났다!!!
'프로그래밍 > Python' 카테고리의 다른 글
| 📔파워 유저를 위한 파이썬 Express 15. 파이썬을 이용한 데이터 과학 (6) | 2025.05.20 |
|---|---|
| 📔파워 유저를 위한 파이썬 Express: 14. 넘파이(Numpy)와 MatPlot (1) | 2025.05.18 |
| 📔파워 유저를 위한 파이썬 Express: 12. 상속 (0) | 2025.05.09 |
| 📔파워 유저를 위한 파이썬 Express 11. 내장함수, 람다식, 제너레이터, 모듈 (0) | 2023.07.13 |
| 📔파워 유저를 위한 파이썬 Express 10. 파일과 예외처리 (0) | 2023.06.18 |