14.1 이번 장에서 만들 프로그램
(1)정규분포 데이터를 생성하고 히스토그램 그리기

(2) 넘파이로 싸인파를 생성하고 matplotlib를 이용하여 그래프로 그리기
14.2 MatPlot
MatPlot: GNUplot처럼 그래프를 그리는 라이브러리
-장점: 파이썬 모듈이라는 점, MATLAB을 대신할 수 있음, 무료이고 오픈소스임
직선그래프
MatPlot에서 그래프는 점이나 막대를 이용하여 데이터의 상관 관계를 알려주는 2차원 또는 3차원 그림
-x축: 독립 변수
-y축: 종속 변수
matplotlib의 하위 모듈인 pyplot을 사용할 것임!!
pyplot은 객체 지향적인 인터페이스 제공
matplotlib.pyplot를 plt 이름으로 사용하는 것은 거의 표준 관행이 됨
우리가 값들의 리스트를 plot()함수로 전달하면, plot() 함수는 이것을 y축 값으로 생각하여 그래프로 그림
x축 값은 리스트의 인덱스라고 생각함
import matplotlib.pyplot as plt
plt.plot([15.6, 14.2, 16.3, 18.2, 17.1, 20.2, 22.4])
plt.show()
x축 값을 별도로 줄 수 있음
첫 번째 항목: x축
두 번째 항목: y축
import matplotlib.pyplot as plt
X = [1, 2, 3, 4, 5, 6, 7]
Y = [15.6, 14.2, 16.3, 18.2, 17.1, 20.2, 22.4]
plt.plot(X, Y)
plt.show()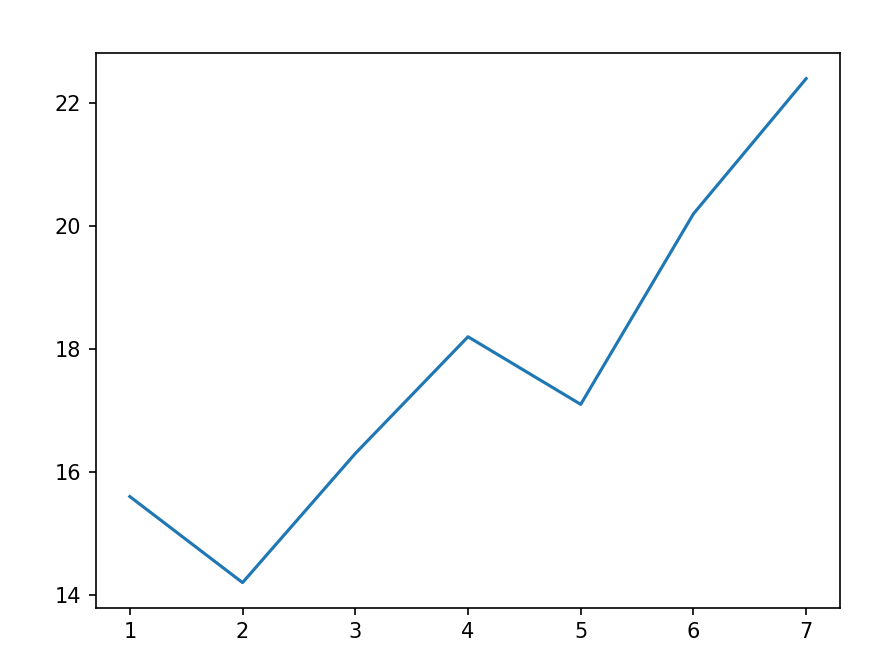
이번엔 요일을 x 축에 표시해보기
import matplotlib.pyplot as plt
X = ["Mon", "Tue", "Wed", "Thur", "Fri", "Sat", "Sun"]
Y = [15.6, 14.2, 16.3, 18.2, 17.1, 20.2, 22.4]
plt.plot(X, Y)
plt.show()
이번에는 하나의 그래프에 2개의 값을 겹쳐서 표시해보기
y축에 해당하는 값을 추가로 입력하면 됨

이번에는 레전드(legend)와 제목 붙여보기
레전드는 y축값이 무엇을 나타내는지를 설명함
import matplotlib.pyplot as plt
X = ["Mon", "Tue", "Wed", "Thur", "Fri", "Sat", "Sun"]
Y1 = [15.6, 14.2, 16.3, 18.2, 17.1, 20.2, 22.4]
Y2 = [20.1, 23.1, 23.8, 25.9, 23.4, 25.1, 26.3]
plt.plot(X, Y1, label="Seoul") #분리시켜서 그려도 됨
plt.plot(X, Y2, label="Busan")
plt.xlabel("day")
plt.ylabel("temperature")
plt.legend(loc="upper left")
plt.title("Temperatures of Cities")
plt.show()
점선 그래프
앞의 그래프를 보면 우리가 전달한 데이터값을 전부 선으로 연결해서 그리는 것을 알 수 있음
만약 데이터 값만을 기호로 표시하고자 한다면 별도의 형식 문자열을 전달하면 됨

import matplotlib.pyplot as plt
plt.plot([15.6, 14.2, 16.3, 18.2, 17.1, 20.2, 22.4], "sm")
plt.show()
막대 그래프

import matplotlib.pyplot as plt
X = ["Mon", "Tue", "Wed", "Thur", "Fri", "Sat", "Sun"]
Y = [15.6, 14.2, 16.3, 18.2, 17.1, 20.2, 22.4]
plt.bar(X, Y)
plt.show()
3차원 그래프
Matplotlib는 처음에는 2차원 그래프 만을 염두에 두고 설계되었지만 이후 버전에서 3차원 데이터 시각화를 위한 도구 세트도 제공함
차원 축은 projection = '3d' 키워드를 전달하여 다음 코드와 같이 생성 가능
배열 X에 x축 데이터가, 배열 Y에 y축 데이터가, 배열 Z에 z축 데이터가 저장됨
이 3개의 배열을 사용하여 3차원 그래프를 그리게 됨

import numpy as np
import matplotlib.pyplot as plt
#3차원 축(axis)을 얻음
axis = plt.axes(projection='3d')
plt.show()
#3차원 데이터를 넘파이 배열로 생성함
Z = np.linspace(0, 1, 100)
X = Z * np.sin(30 * Z)
Y = Z * np.cos(30 * Z)
#3차원 그래프를 그림
axis.plot3D(X, Y, Z)
14.3 넘파이 기초
넘파이란?
넘파이(NumPy): 행렬(matrix) 계산을 위한 파이썬 라이브러리 모듈
"NumPy" = "Numerical Python"의 약자
넘파이는 C언어로 작성되어 있어 매우 빠른 속도를 자랑함
처리 속도가 중요한 인공지느이나 데이터 과학에서는 파이썬의 리스트 대신에 넘파이를 선호함
기계 학습 프로그램을 작성하는 데 사용되는 scikit-learn이나 tensorflow 패키지도 모두 넘파이 위에서 작동하기 때문
파이썬의 리스트에서는 데이터가 비연속적인 위치에 저장됨 -> 대랴의 데이터를 처리할 때 상당히 불리
반면에 넘파이 2차원 배열은 데이터들이 연속적인 위치에 저장되어서 아주 효율적으로 데이터를 저장하고 처리할 수 있음
데이터가 연속적으로 저장되어야 다음 데이터를 찾기 쉽기 때문
넘파이의 핵심적인 객체: 다차원 배열(행렬)
넘파이는 성능이 우수한 "ndarray"(n차원 배열의 약자) 객체를 제공
"ndarray"객체 - 동일한 자료형의 항목들을 저장할 수 있음
ex) 정수들의 2차원 배열을 넘파이로 생성할 수 있음
배열이기 때문에 각 축(axis)의 인덱스를 이용해서 각 요소를 빠르게 추출할 수 있음
1차원 배열
넘파이를 사용하기 위해서 가장 먼저 해야 할 일: numpy 패키지를 포함시키는 작업
관행적으로 넘파이는 np라는 별명으로 포함됨
import numpy as np우리가 화씨 온도로 저장된 뉴욕의 기온 데이터를 얻었다고 가정
ftemp = [63, 73, 80, 86, 84, 78, 66, 54, 45,63]이것을 넘파이로 배열로 변환하려면 다음과 같이 넘파이 모듈의 array() 함수를 호출
import numpy as np
ftemp = [63, 73, 80, 86, 84, 78, 66, 54, 45,63]
F = np.array(ftemp)
F>>>[63 73 80 86 84 78 66 54 45 63]
a = np.array([1, 2, 3])
a: 배열 객체
array: 생성자 함수
[1, 2, 3]: 파이썬 리스트
(F-32)*5/9>>>[17.22222222 22.77777778 26.66666667 30. 28.88888889 25.55555556
18.88888889 12.22222222 7.22222222 17.22222222]
ctemp = [(t-32)*4/9 for t in ftemp]
print(ctemp)>>>[13.777777777777779, 18.22222222222222, 21.333333333333332, 24.0, 23.11111111111111, 20.444444444444443, 15.11111111111111, 9.777777777777779, 5.777777777777778, 13.777777777777779]

y축에 배열 F의 값을 표시
배열 F의 인덱스가 x축으로 사용됨
배열 간의 연산
넘파이 배열에는 + 연산자나 * 연산자와 같은 수학적인 연산자 적용 가능
배열에 대한 모든 산술 연산자는 요소별로 적용됨
산술 연산이 적용되면 새로운 배열이 생성되고 결과값으로 채워짐
A = np.array([1, 2, 3, 4])
B = np.array([5, 6, 7, 8])
result = A + B
result>>>
array([ 6, 8, 10, 12])
넘파이에서는 덧셈 뿐만 아니라 -, *, /와 같은 산술 연산도 배열의 요소별로 적용됨
상상할 수 있는 모든 연산자 적용 가능
<와 > 같은 비교 연산자도 적용 가능
비교 연산자도 배열의 요소별로 적용됨
a = np.array([0, 9, 21, 3])
a < 10array([ True, True, False, True])
2차원 배열
넘파이를 이용하면 1차원, 2차원, 3차원 배열을 모두 생성할 수 있음
넘파이 배열을 적절하게 생성하기만 해도, 상당히 쓸모가 많음
2차원 배열도 넘파이로 쉽게 만들 수 있음
np.array()를 호출하고 파이썬 2차원 리스트를 전달해 생성 가능
넘파이의 2차원 배열은 수학에서의 행렬(matrix)와 같음
b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
barray([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
2차원 배열에서 특정한 위치에 있는 요소 어떻게 꺼낼까?
2차원 배열도 인덱스를 사용함
다만 2차원이기 때문에 인덱스가 2개 필요함
첫 번째 인덱스: 행의 번호
두 번재 인덱스: 열의 번호
b[0][2]np.int64(3)
넘파이는 각 배열마다 타입이 하나만 있다고 생각한다.
넘파이의 배열 안에는 동일한 타입의 데이터만 저장할 수있다.
정수면 정수, 실수면 실수만을 저장할 수 있는 것!
파이썬의 리스트처럼 여러 가지 타입을 섞어서 저장할 수는 없음
만약 여러 가지 타입을 섞어서 넘파이의 배열에 전달하면 넘파이는 이것을 전부 문자열로 변경함
LAB: BMI 계산하기
각 실험 대상자들의 체질량 지수 (BMI) 계산하기
우선 첫 번째 실험 대상자의 bmi구하기
나머지 사람들의 BMI도 마찬가지로 계산
import numpy as np
heights = [1.83, 1.76, 1.69, 1.86, 1.77, 1.73]
weights = [86, 74, 59, 95, 80, 68]
np_heights = np.array(heights)
np_weights = np.array(weights)
bmi = np_weights/(np_heights**2)
print(bmi)[25.68007405 23.88946281 20.65754 27.45982194 25.53544639 22.72043837]
14.4 넘파이 데이터 생성 함수들
arange() 함수
arrange() 함수를 사요하면 연속되는 정수를 가지는 넘파이 배열을 쉽게 만들 수 있다.
반복 구조에서 사용되는 파이썬 range() 함수와 사용법이 같다.
np.arrange(start, stop, step)
-start: 시작값
-stop: 종료값
-step: 간격
np.arrange(1, 10, 2)는 1에서 시작해서 10보다 작을 때까지 2씩 증가하면서 배열 생성함
A = np.arange(1, 10, 2)
Aarray([1, 3, 5, 7, 9])
import matplotlib.pyplot as plt
plt.plot(A)
plt.show()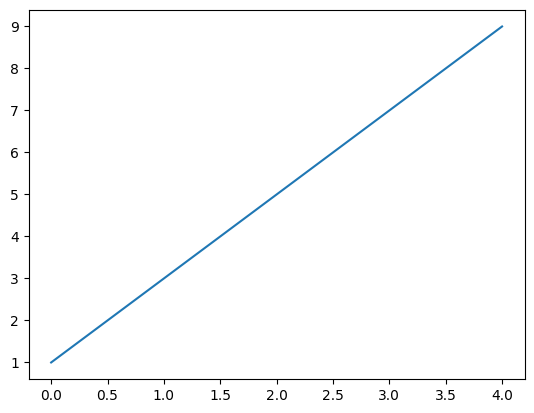
linspace() 함수
linspace()는 시작값부터 종료값까지 균일한 간격으로 값들을 생성하여 배열로 반환함
np.linspace(start, stop, num)
-start: 시작값
-stop: 종료값
-step: 개수
A = np.linspace(0, 10, 100)
Aarray([ 0. , 0.1010101 , 0.2020202 , 0.3030303 , 0.4040404 ,
0.50505051, 0.60606061, 0.70707071, 0.80808081, 0.90909091,
1.01010101, 1.11111111, 1.21212121, 1.31313131, 1.41414141,
1.51515152, 1.61616162, 1.71717172, 1.81818182, 1.91919192,
2.02020202, 2.12121212, 2.22222222, 2.32323232, 2.42424242,
2.52525253, 2.62626263, 2.72727273, 2.82828283, 2.92929293,
3.03030303, 3.13131313, 3.23232323, 3.33333333, 3.43434343,
3.53535354, 3.63636364, 3.73737374, 3.83838384, 3.93939394,
4.04040404, 4.14141414, 4.24242424, 4.34343434, 4.44444444,
4.54545455, 4.64646465, 4.74747475, 4.84848485, 4.94949495,
5.05050505, 5.15151515, 5.25252525, 5.35353535, 5.45454545,
5.55555556, 5.65656566, 5.75757576, 5.85858586, 5.95959596,
6.06060606, 6.16161616, 6.26262626, 6.36363636, 6.46464646,
6.56565657, 6.66666667, 6.76767677, 6.86868687, 6.96969697,
7.07070707, 7.17171717, 7.27272727, 7.37373737, 7.47474747,
7.57575758, 7.67676768, 7.77777778, 7.87878788, 7.97979798,
8.08080808, 8.18181818, 8.28282828, 8.38383838, 8.48484848,
8.58585859, 8.68686869, 8.78787879, 8.88888889, 8.98989899,
9.09090909, 9.19191919, 9.29292929, 9.39393939, 9.49494949,
9.5959596 , 9.6969697 , 9.7979798 , 9.8989899 , 10. ])
균일 분포 난수 생성
시뮬레이션을 위해 난수 데이터를 생성할 수도 있음
넘파이에서 난수의 시드(seed)를 설정하는 문장은 다음과 같음
np.random.seed(100)시드가 설정되면 다음과 같은 문장을 수행하여 5개의 난수를 얻을 수 있다.
난수는 0.0에서 1.0 사이의 값으로 생성된다.
np.random.rand(5)array([0.54340494, 0.27836939, 0.42451759, 0.84477613, 0.00471886])
💥 여기서 잠깐!
Seed: 무작위 숫자 생성기를 고정시키는 것
🎲 그럼 seed가 하는 일은 뭐냐면?
무작위 숫자를 "예측 가능한 무작위"로 바꿔줘!
즉, 무작위(random)인데 항상 같은 결과를 얻게 해줘!
✅ 예를 들어볼게
import numpy as np
np.random.seed(100)
print(np.random.randint(1, 100)) # 항상 같은 숫자 나옴!📌 왜 필요할까?
| 디버깅할 때 | 코드가 항상 같은 무작위값을 출력해서 버그 찾기 쉬워짐 |
| 머신러닝 실험 | 실험마다 결과가 바뀌지 않게 공정한 비교 가능 |
| 예시 코드 만들기 | 다른 사람도 같은 결과 보게 하고 싶을 때 |
🎯 비유로 말하자면:
- seed 없이: 매번 주사위를 굴릴 때 결과가 바뀜 (진짜 랜덤)
- seed 주면: "이렇게 굴리면 이 순서로 나올 거야!" 라는 시나리오를 기억해둠
🔁 한 줄 요약
np.random.seed(숫자)는 랜덤 결과를 고정시켜서,
실행할 때마다 같은 랜덤 값을 나오게 해주는 장치야!
난수로 이루어진 2차원 배열(크기=5X3)을 얻으려면 다음과 같이 한다.
np.random.rand(5, 3)array([[0.12156912, 0.67074908, 0.82585276],
[0.13670659, 0.57509333, 0.89132195],
[0.20920212, 0.18532822, 0.10837689],
[0.21969749, 0.97862378, 0.81168315],
[0.17194101, 0.81622475, 0.27407375]])
특정 범위의 난수 생성하기
ex) 10~20사이에 있는 난수 5개를 생성하는 문장은 다음과 같음
a=10
b=20
(b-a)*np.random.rand(5)+aarray([14.31704184, 19.4002982 , 18.17649379, 13.3611195 , 11.75410454])
정규 분포 난수 생성
앞에서 생성한 난수는 균일한 확률 분포에서 만들어짐
만약 정규 분포에서 난수를 생성하려면? rand() 사용하기
ex) 정규분포에서 난수 5개 생성하려면 다음과 같은 문장 사용하기
*randn()에서 뒤에 붙은 n은 "normal distribution"을 의미함
n이 없으면 균일분포이고, n이 있으면 정규 분포
np.random.randn(5)array([ 0.78148842, -0.65438103, 0.04117247, -0.20191691, -0.87081315])
난수로 채워진 5X4 크기의 2차원 배열을 생성하려면 다음과 같이 적어주기
np.random.randn(5, 4)array([[ 0.22893207, -0.40803994, -0.10392514, 1.56717879],
[ 0.49702472, 1.15587233, 1.83861168, 1.53572662],
[ 0.25499773, -0.84415725, -0.98294346, -0.30609783],
[ 0.83850061, -1.69084816, 1.15117366, -1.02933685],
[-0.51099219, -2.36027053, 0.10359513, 1.73881773]])
위의 정규 분포는 평균값이 0이고 표준편차가 1.0
만약 평균값과 표준편차를 다르게 하려면 다음과 같이 하면 됨
m, sigma = 10, 2
m + sigma*np.random.randn(5)array([12.48375169, 10.26482551, 11.15558791, 6.84818858, 7.41441153])
넘파이에는 정규 분포의 평균값과 표준편차를 인수로 보낼 수 있는 함수 normal()도 있다.
randn()의 조금 편리한 버전
a = np.random.normal(loc=0.0, scale=1.0, size=None)
loc: 평균
scale: 표준편차
size: 배열의 차원
앞의 코드를 normal()을 이용하여 다시 작성하면 다음과 같다.
mu, sigma = 0, 0.1
np.random.normal(mu, sigma, 5)array([-0.06599198, -0.08740048, -0.06895506, -0.05354798, 0.1527953 ])
LAB: 잡음이 들어간 직선 그리기
linspae() 함수와 random.normal() 함수 사용해보기
import numpy as np
import matplotlib.pyplot as plt
pure = np.linspace(1, 10, 100) #1부터 10까지 100개의 데이터 생성
noise = np.random.normal(0, 1, 100) #평균이 0이고 표준편차가 1인 100개 난수 생성
#넘파이 배열 간 덧셈 연산, 요소별로 덧셈이 수행됨
signal = pure + noise
#선 그래프를 그림
plt.plot(signal)
plt.show()
14.5 넘파이 내장 함수
넘파이 배열에 함수를 적용하면 어떻게 되는지 알아보기!
ex) 넘파이의 sin() 함수를 적용하면 배열의 요소에 모두 sin() 함수가 적용됨
A = np.array([0, 1, 2,3])
10 * np.sin(A)array([0. , 8.41470985, 9.09297427, 1.41120008])
넘파이는 배열의 데이터를 사용해 계산을 수행하는 다양한 메소드를 가진다.
기본적으로 이러한 메소드는 배열의 형태를 모양을 무시하고 계산에 모든 요소를 사용함.
활용
-> 배열의 형태와는 관계없이 배열의 평균 계산
배열의 mean() 메소드를 호출하면, mean() 메소드는 전체 요소의 합계를 계산한 후에 전체 요소 수로 나눔
각 차원에서도 이러한 계산 수행 가능
ex) 2차원 배열에서 각 행의 평균과 각 열의 평균 계산 가능
구체적인 ex>
학생 4명의 3과목 성적(국어, 영어, 수학)이 넘파이 배열에 저장되어 있다고 가정
import numpy as np
scores = np.array([[99, 93, 60], [98, 82, 93], [93, 65, 81], [78, 82, 81]])sum(), min(), max(), mean(), std(), var() 메소드 사용하기
전체 합계는 sum()을 계산할 수 있음
min(), max(): 최저점수와 최대점수 알 수 있음
mean(): 모든 과목의 평균 성적
std(): 표준편차
var(): 성적의 분산

넘파이가 강력한 것은 이러한 계산을 특정한 행이나 열만을 가지고도 할 수 있다는 점
axis라는 매개 변수를 이용하면 됨
axis가 계산을 해야 하는 행이나 열을 지정
axis=0이라면 2차원 행렬에서 axis=0인 직선을 따라서 통계값이 계산함
scores.mean(axis=0)array([92. , 80.5 , 78.75])
위의 계산에서 92는 99, 98, 93, 78의 평균
즉 특정한 과목의 평균 성적
mean(axis=1)로 해서 평균을 계산하면 다음과 같음
scores.mean(axis=1)array([84. , 91. , 79.66666667, 80.33333333])위의 계산에서 84는 99, 93, 60의 평균
즉, 특정한 학생의 평균 성적이다.
히스토그램
히스토그램은 수치 데이터의 빈도를 그래픽으로 표현한 것
ex) 정규 분포에서 생성된 각 값들이 어떤 구간에 가장 많이 있는지를 히스토그램으로 그려보
import matplotlib.pyplot as plt
import numpy as np
numbers = np.random.normal(size=10000)
plt.hist(numbers)
plt.xlabel("value")
plt.ylabel("freq")
plt.show()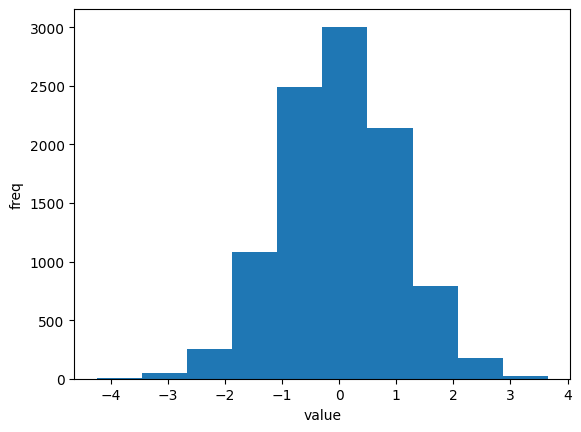
위의 코드에서 plt.hist(numbers)가 히스토그램을 생성하고 화면에 그리는 명령문
number 안에 들어 있는 10000개의 난수에 대하여 각 구간별로 몇 개씩의 난수가 들어 있는지를 계산해서 히스토그램을 자동으로 그린다.
가우시안 분포에서 생성한 난수이므로 평균값인 0 주변의 값이 제일 많을 것으로 예상된다.
LAB: 정규 분포 그래프 그리기
np.randomrandn(10000)은 평균이 0인 정규분포에서 10000개의 난수를 생성한다.
수식 m+sigam*np.randm.randn(10000)은 평균이 m이고 표준편차가 sigma인 정규분포에서 난수를 생성한다.
import numpy as np
import matplotlib.pyplot as plt
m, sigma = 10, 2
Y1 = np.random.randn(10000)
Y2 = m+sigma*np.random.randn(10000)
plt.figure(figsize=(10,6))
plt.hist(Y1, bins=20)
plt.hist(Y2, bins=20)
plt.show()
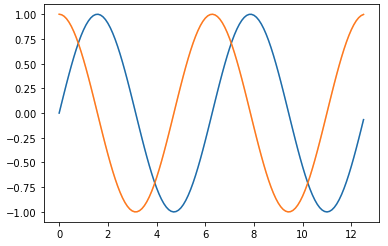
LAB: 싸인 함수 그리기
넘파이를 이용하면 일정 간격의 데이터를 쉽게 생성할 수 있음
linspace() 수를 사용해서 일정 간격의 데이터를 만들고 넘파이의 sin() 함수에 이 데이터를 전달해서 싸인 값을 얻는다.
import matplotlib.pyplot as plt
import numpy as np
#-2𝝿에서 +2𝝿까지 100개의 데이터를 균일하게 생성
X = np.linspace(-2 * np.pi, 2*np.pi, 100)
#넘파이 배열에 sin() 함수 적용
Y1 = np.sin(X)
Y2 = 3 * np.sin(X)
plt.plot(X, Y1, X, Y2)
plt.show()
LAB: MSE 오차 계산하기
기계 학습에서는 평균 제곱 오류(MSE, mean sqare error)가 많이 계산됨
ex) 회귀 문제나 분류 문제에서 실제 출력과 우리가 원하는 출력 간의 오차를 계산하기 해 MSE를 많이 계산함

여기서 yi는 기계학습 모델에 의해 예측된 값이고 yi^는 우리가 원하는 값
yi를 ypred로 쓰고 i^는 y라고 쓰자.
ypred와 y 모두 넘파이 배열이라고 가정
따라서 배열의 크기에 상관없이 다음과 같은 명령문으로 MSE 오류 계산 가능
MSE = (1/n) * np.sum(np.square(ypred - y))
import numpy as np
ypred = np.array([1, 0, 0, 0, 0])
y = np.array([0, 1, 0, 0, 0])
n = 5
MSE = (1/n) * np.sum(np.square(ypred-1))
print(MSE)0.8
16.6인덱싱과 슬라이싱
파이썬 리스트-> 인덱싱/ 슬라이싱 O
넘파이 배열-> 인덱싱/ 슬라이싱 O
인덱싱과 슬라이싱
성적이 저장된 1차원 배열에서 요소들을 꺼내는 방법 알아보기
grades = np.array([88, 72, 93, 94])
1에서 2까지의 슬라이스는 다음과 같이 얻을 수 있음
grades[1:3]array([72, 93])
다음과 같이 시작 인덱스나 종료 인덱스는 생략 가능
grades[:2]array([88, 72])
논리적인 인덱싱
논리적인 인덱싱(logical indexing): 어떤 조건을 주어서 배열에서 원하는 값을 추려내는 것
ex)사람들의 나이가 저장된 넘파이 배열 ages가 있다고 하자
ages = np.array([18, 19, 25, 30, 28])
ages에서 20살 이상인 사람만 고르려고 하면 다음과 같은 조건식을 써준다
y=ages>20
yarray([False, False, True, True, True])
결과는 부울형의 넘파이 배열이 된다.
그런데 실제로는 배열 중에서 20살 이상인 사람들을 뽑아내는 연산이 많이 사용된다.
이때는 위의 부울형 배열을 인덱스로 하여 배열ages에 보내면 된다.
이것을 논리적인 인덱싱이라고 한다.
y=ages>20
yarray([False, False, True, True, True])조건을 주어진 배열 중에서 원하는 요소들을 선택할 수 있다.
2차원 배열의 슬라이싱
넘파이에서 슬라이싱은 큰 행렬에서 작은 행렬을 끄집어내는 것으로 이해하면 됨
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
a[0:2, 1:3]array([[2, 3],
[5, 6]])✂️ 이 슬라이싱 뜻은?
a[0:2, 1:3]
→ 행은 0부터 2 전까지,
→ 열은 1부터 3 전까지
* 2차원 넘파이 배열과 2차원 파이썬 리스트에서 슬라이스를 지정하는 방법이 약간 다르다.
넘파이에서는 a[0:2, 1:3]과 같이 지정하지만 2차원 파이썬 리스트에서는 a[0:2][1:3]과 같이 지정한다.
넘파이에서는 항상:
a[행 시작:끝, 열 시작:끝]
행 먼저, 열 나중!
2차원 배열에서도 어떤 조건을 주어서 조건에 맞는 값들만 추려낼 수 있다.
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
a>5array([[False, False, False],
[False, False, True],
[ True, True, True]])2차원 배열도 마찬가질 위와 같이 True, False로 이루어진 배열이 반환됨
이것을 이용하여 특정한 값들을 뽑아내려면 다음과 같이 하면 됨
실행 결과는 1차원 행렬이 된다.
a[a > 5]array([6, 7, 8, 9])
LAB: 월급 인상하기
현재 직원들의 월급이 [220, 250, 230]이라고 하자. 사장님이 월급을 100만원식 올려주기로 하셨다. 넘파이를 이용하여 계산해보자.
import numpy as np
salary = np.array([220, 250, 330])넘파이 배열에 저장된 모든 값에 100을 더하려면 다음과 같이 배열에 100을 더하면 됨
salary = salary + 100
salaryarray([320, 350, 430])위의 코드에서 salary에 100을 더하면 salary 배여르이 모든 요소에 100이 더해진다.
이것을 들은 다른 사장님은 모든 직원들의 월급을 2배 올려주기로 하셨다. 어떻게 하면 될까? 월급이 450만원 이상인 직원을 찾고 싶으면 어떻게 하면 될까?
넘파이의 배열에 2를 곱하면 된다.
salary = np.array([220, 250, 230])
salary = salary * 2
salaryarray([440, 500, 460])월급이 450만원 이상인 직언을 찾고 싶으면 어떻게 하면 될까?
salary>450array([False, True, True])
LAB: 그래프 그리기
넘파이는 MatPlot과 아주 잘 연결된다. 넘파이로 데이터를 만들고 이것을 MatPlot으로 그릴 수 잇다.
linspace()로 x축값을 생성하고 f(x)=1, f(x)=x, f(x)=x^2의 그래프를 함께 그려보자.
import matplotlib.pyplot as plt
import numpy as np
X = np.arange(0, 10)
Y1 = np.ones(10) #ones()는 0으로 이루어진 넘파이 배열 생성
Y2 = X
Y3 = X**2
#3개의 그래프를 하나의 축에 그린다.
plt.plot(X, Y1, X, Y2, X, Y3)
plt.show()
14.7 약간의 수치해석
넘파이는 행렬 라이브러리. 따라서 전치 행렬이나 역행렬을 계산하는 메소드가 제고오딘다. 방정식을 푸는 메소드도 제공된다.
전치 행렬은 딥러닝의 "역전파" 학습 과정에서 사용된다.
전치 행렬 계산하기
행렬 A가 주어졌을 때 그 행렬 A에서 행과 열을 바꾼 행렬을 행렬 A의 전치행렬이라고 한다.
넘파이의 transpose()를 호출해도 되고, 아니면 속성 T를 참조하면 된다.
x = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
x.transpose()array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])x.Tarray([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
역행렬 계산하기
넘파이 안에는 LAPACK이 내장되어 있다.
np.linalg.inv(x)와 같이 역행렬을 계산한다.
원래 행렬과 역행렬을 곱하면 단위 행렬이 되어야 한다.
넘파이 용어로 하면 dot(a, ainv) = do(ainv, a) = eye(a.shape[0])이다.
x = np.array([[1,2], [3,4]])
y = np.linalg.inv(x)
yarray([[-2. , 1. ],
[ 1.5, -0.5]])np.dot(x, y)array([[1.0000000e+00, 0.0000000e+00],
[8.8817842e-16, 1.0000000e+00]])
선형 방정식 풀기
선형 방정식도 넘파이를 이용하여 계산할 수 있다. 선형 방정식이 해를 가지려면 여러 가지 조건이 만족되어야 한다.
예를 들어서 3*x0+x1=0와 x0+2*x1=8가 주어졌을 때, 이들 방정식을 만족하는 해는 다음과 같이 계산한다.
a = np.array([[3, 1], [1, 2]])
b = np.array([9, 8])
x = np.linalg.solve(a, b)
xarray([2., 3.])'프로그래밍 > Python' 카테고리의 다른 글
| 📔파워 유저를 위한 파이썬 Express 16. 파이썬을 이용한 기계 학습 (2) | 2025.05.23 |
|---|---|
| 📔파워 유저를 위한 파이썬 Express 15. 파이썬을 이용한 데이터 과학 (6) | 2025.05.20 |
| 📔파워 유저를 위한 파이썬 Express: 12. 상속 (0) | 2025.05.09 |
| 📔파워 유저를 위한 파이썬 Express 11. 내장함수, 람다식, 제너레이터, 모듈 (0) | 2023.07.13 |
| 📔파워 유저를 위한 파이썬 Express 10. 파일과 예외처리 (0) | 2023.06.18 |