SQLD 복습
과목1. 데이터 모델링의 이해
제1장. 데이터 모델링의 이해
- 1절. 데이터 모델의 이해
- 2절. 엔터티
- 3절. 속성
- 4절. 관계
- 5절. 식별자
📝사용자가 처리하는 프로세스 혹은 이와 관련된 프로그램과 테이블의 연계성을 높이는 것은 데이터모델이 업무변경에 대해 취약하게 만드는 단점
📇비유연성(Inflexibility)
: 데이터 모델을 어떻게 설계했느냐에 따라 사소한 업무 변화에도 데이터 모델이 수시로 변경됨으로써 유지보수의 어려움을 가중시킬 수 있음
데이터의 정의를 데이터의 사용 프로세스와 분리함으로써 데이터 모델링은 데이터 혹은 프로세스의 작은 변화가 애플리케이션과 데이터베이스에 중대한 변화를 일으킬 수 있는 가능성을 줄임
📇개념 스키마(Conceptual Schema)
: 통합 관점의 스키마를 표현한 것
-데이터 모델링: 통합 관점의 뷰를 가지고 있는 개념 스키마를 만들어 가는 과정
📇ERD 작성하는 방법
엔터티 도출->엔터티 배치->관계 설정->관계명 기술
📇엔터티의 특징
- 속성이 없는 엔터티는 있을 수 없음. 엔터티는 반드시 속성을 가져야 함.
- 엔터티는 다른 엔터티와 관계가 있을 수밖에 없음. 단, 통계성 엔터티나 코드성 엔터티의 겨웅 관계 생략 가능
- 데이터로서 존재하지만 업무에서 필요로 하지 않으면 해당 업무의 엔터티로 성립될 수 없음
엔터티(Entity) = 테이블=릴레이션
엔터티는 업무에서 필요하고 유용한 정보를 저장하고 관리하기 위한 집합적인 것이다. 개념, 사건, 장소 등의 명사(Things)이다.
속성(Attribute) = 컬럼=차수(디그리: 속성의 수)
속성은 업무에서 필요로 하는 인스턴스로 의미상 더 이상 분리되지 않는 최소의 데이터 단위이다.
인스턴스(Instance) = 행=튜플 (카디널리티: 튜플의 수)
인스턴스는 데이터베이스에 저장된 데이터 내용의 전체 집합을 의미한다.
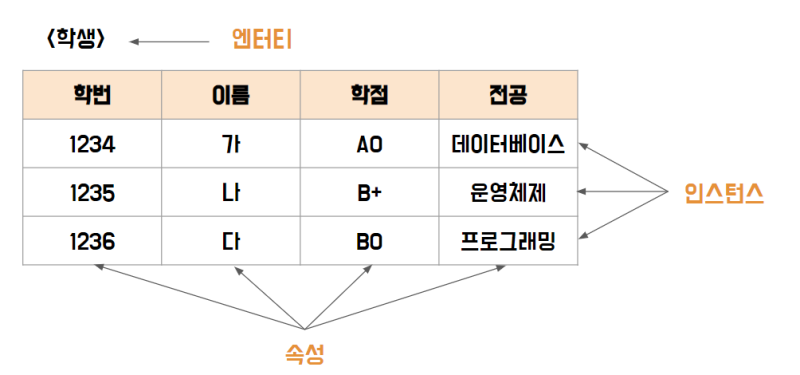
📇개념 엔터티
: 자신의 고유한 주식별자 가짐
ex) 사원, 부서, 고객 ...
📇엔터티 이름을 부여하는 방법
-엔터티가 생성되는 의미대로 자연스럽게 부여하도록 한다.
📇속성(Attribute)
: 업무에서 필요로 하는 인스턴스에서 관리하고자 하는 의미상 더이상 분리되지 않는 최소의 단위
-하나의 인스턴스에서 각각의 속성은 한 개의 속성값을 가져야 한다.
📝이자는 계산된 값으로 파생속성이 맞지만, 이자율은 원래 가지고 있어야 하는 속성이므로 기본속성에 해당
📇파생속성
: 데이터를 조회할 때 빠른 성능을 낼 수 있도록 하기 위해 원래 속성의 값을 계산하여 저장할 수 있도록 만든 속성
📇데이터 모델링의 관계
- 데이터 모델링에서는 존재적 관계와 행위에 의한 관계를 구분하는 표기법이 없으며, UML에서는 연간관계와 의존관계에 대해 다른 표기법을 가지고 표현하게 되어 있음
- 관계는 존제에 의한 관계와 행위에 의한 관계로 구분될 수 있으나 ERD에서는 관계를 연결할 때, 존재와 행위를 구분하지 않고 단일화된 표기법 사용
- UML에는 클래스 다이어그램의 관계 중 연관관계(Associate)와 의존관계(dependency)가 있고, 이것은 실선과 점선의 표기법으로 다르게 표현됨
- (존재+행위) 연관/의존
📇식별자 관계
- 엔터티가 같이 소멸되는 경우는 식별자 관계로 정의하는 것이 바람직
📇두 개의 엔터티 사이에서 관계를 도출할 때 체크할 사항
- 연관규칙 존재?
- 정보 조합 발생?
- 업무 기술서, 장표에 관계 연결에 대한 규칙 서술
- 동사(Verb)가 있는가
📇식별자의 종류
- 대표성; 주식별자(Primary Identifier) / 보조 식별자(Alternate Identifier)
- 스스로 생성: 내부 식별자 / 외부 식별자(Foreign Identifier)
- 단일속성 식별 여부: 단일 식별자(Simple Identifier) / 복합 식별자(Composit Identifier)
- 새로움: 본질 식별자 / 인조 식별자
📇데이터 모델링 단계 (수행절차)
- 데이터 모델링을 할 때 정규화를 정확하게 수행
- 데이터베이스 용량산정 수행
- 데이터베이스에 발생되는 트랜잭션의 유형 파악
- 용량과 트랜잭션의 유형에 따라 반정규화를 수행
- 이력 모델의 조정, PK/FK 조정, 슈퍼타입/서브타입 조정 등을 수행
- 성능 관점에서 데이터모델 검증
-> 성능을 고려한 데이터 모델링은 정규화를 수행한 이후에 용량산정과 트랜잭션 유형을 파악하여 반정규화를 수행.
PK/FK 등을 조정하여 인덱스의 특징을 반영한 데이터 모델로 만들고 이후에 데이터모델을 검증하는 방법으로 전개
📇성능데이터 모델링 고려사항
- 이력데이터는 시간에 따라 반복적으로 발생이 되기 때문에 대량 데이터일 가능성이 높아 특별히 성능을 고려하여 칼럼 등을 추가하도록 설계해야 함
📇정규형
: 릴레이션이 정규화된 정도
📝컬럼 단위에서 중복된 경우도 1차 정규화의 대상이 된다. 이에 대한 분리는 1:M의 관계로 두 개의 엔터티로 분리됨
📇반정규화 고려할 때 판단 요소
- 반정규화 정보에 대한 재현의 적시성으로 판단
ex) 빌링의 잔액(balance)은 다수 테이블에 대한 다량의 조인이 불가피하므로 데이터 제공의 적시성 확보를 위한 필수 반정규화 대상 정보
- 대량 데이터 탐색의 경우 인덱스가 아닌 파티션 및 데이터 클러스터링 등의 다양한 물리 저장 기법을 활용하여 성능 개선을 유도할 수 있음. 다만, 하나의 결과셋을 추출하기 위해 다량의 데이터를 탐색하는 처리가 반복적으로 발생한다면 이때는 반정규화를 고려하는 것이 좋음
- 이전 또는 이후 위치의 레코드에 대한 탐색은 window function으로 접근 가능
- 집계 테이블 이외에도 다양한 유형(다수 테이블의 키 연결 테이블 등)에 대하여 반정규화 테이블 적용이 필요할 수 있음
📇부분테이블 추가
: 하나의 테이블의 전체 칼럼 중 자주 이용하는 집중화된 칼럼들이 있을 때 디스크 I/O를 줄이기 위해 해당 칼럼들을 별도로 모아 놓는 반정규화 기법
📇반정규화 기법
- 중복 칼럼 추가
- 파생 칼럼 추가
- 이력 테이블에 기능 칼럼 추가
FK에 대한 속성 추가!= 반정규화 기법
-데이터 모델링에서 관계를 연결할 때 나타나는 자연스러운 현상
📝최근에 변경된 값만을 조회할 경우 과도한 조인으로 인해 성능이 저하되어 나타나게 된다.
📇칼럼 수가 많은 테이블
- 로우체이닝이 발생할 정도로 한 테이블에 많은 칼럼들이 존재할 경우 조회 성능 저하가 발생할 수 있다.
트랜잭션이 접근하는 칼럼 유형을 분석하여 1:1로 테이블을 분리하면 디스크 I/O가 줄어들어 조회 성능을 향상시킬 수 있다.
🍋로우체이닝: 한 로우의 데이터 크기가 블록의 데이터 저장 공간보다 클때 발생하는 현상이다. 데이터 크기가 블록의 데이터 저장공간보다 클때 한 로우를 여러개의 조각으로 분리하고 각 조각을 다른 블록에 저장한다.
한 로우의 데이터 크기가 블록의 데이터 저장 공간보다 클때 발생하는 현상이다. 데이터 크기가 블록의 데이터 저장공간보다 클때 한 로우를 여러개의 조각으로 분리하고 각 조각을 다른 블록에 저장한다.
📏47번 문제
개별 테이블을 모두 조회하는 트랜잭션이 대부분이라는 가정이 있으므로 UNION/UNION ALL 할 경우 개별조회에 따른 시간소요와 이것을 조합하는 성능저하 발생
따라서 하나의 테이블로 통합하도록 하고 대신 PK 체계나 일반속성에 각 사건을 구분할 수 있도록 구분자 부여
📇논리 데이터모델의 슈퍼타입과 서브타입 데이터모델을 물리적인 테이블 형식으로 변활할 때
- 트랜잭션은 항상 전체를 통합하여 분석 처리하는데 슈퍼-서브 타입이 하나의 테이블로 통합되어 있으면 하나의 테이블에 집적된 데이터만 읽어 처리할 수 있기 때문에 다른 형식에 비해 성능이 더 우수(조인 감소)
- 트랜잭션은 항상 전체를 대상으로 일괄처리하는데, 테이블은 서브타입별로 개별 유지하는 것으로 변환하면 UNION 연산에 의해 성능이 저하될 수 있음
- 트랜잭션은 항상 서브타입 개별로 처리하는데 테이블을 하나로 통합하여 변환하면 불필요하게 많은 양의 데이터가 집적되어 있어 성능이 저하될 수 있음
- 트랜잭션은 항상 슈퍼+서브 타입을 함께 처리하는데 개별로 유지하면 조인에 의해 성능이 저하될 수 있음
📇인덱스 액세스 범위를 좁히는 법
인덱스는 값의 범위에 따라 일정하게 정렬이 되어 있으므로 상수값으로 EQUAL 조건으로 조인되는 칼럼이 가장 앞으로 나오고, 범위 조회하는 유형의 칼럼이 그 다음에 오도록 부여하는 것이 인덱스 액세스 범위를 좁힐 수 있는 가장 좋은 방법이 됨
📇분산 데이터베이스
- Global Single Instance(GSI)는 통합된 한 개의 인스턴스, 통합된 데이터베이스 구조를 의미하므로, 분산데이터베이스와는 대치되는 개념
- 공통 코드, 기준 벙보 등 마스터데이터는 분산데이터베이스에 복제 분산 적용
- 거의 실시간(Near Rear Time) 업무적인 특성을 가지고 있을 때 분산 데이터 베이스 사용하여 구성
- 백업 사이트를 구성할 때 간단하게 분산 기능을 적용하여 구성 가능
'프로그래밍 > SQL' 카테고리의 다른 글
| 프로그래머스 SQL 고득점 KIT: GROUP BY (0) | 2023.06.26 |
|---|---|
| 프로그래머스 SQL 고득점 QIT: SELECT (0) | 2023.06.23 |
| 프로그래머스 고득점 SQL KIT - 최솟값 구하기 (0) | 2022.07.23 |
| 프로그래머스 SQL 고득점 KIT - 여러 기준으로 정렬하기 (0) | 2022.07.22 |