3월 23일 금요일 수업내용
사실 금요일날 학교가는 바람에 수업을 듣질 못했다.
맨 뒷자리에 앉아 이어폰 꽂고 어떻게든 들으려고 했는데 교수님이 5분에 한 번씩 내이름을 부르신다.
ㅋㅋ첫날 앞자리에 앉았다가 부담을 느끼고 맨 뒷자리에 앉았는데 이제 10분에 한 번씩 뒷자리로 오신다....
컴퓨터 수업상 한 번 놓치면 그 흐름을 따라갈 수 없어서 그냥 편하게 강사님 목소리만 듣고
주말을 이용해 녹화본을 보며 학습한다.
오히려 이게 더 편한게 혼자 자율적으로 녹화본 들으면서 학습하면
시간을 내 마음대로 유동적으로 쓸 수 있고, 1시간동안 수업들었던 내용을 내가 이해될 때까지 시간 압박에 구애받지 않고 복습을 하니까 학습 효과가 더 있다.
물론 월요일부터 목요일까지는 정해진 시간에 따라야해서 최대한 쉬는 시간을 활용해 복습을 하려고 한다.
하지만 수업듣다가 지쳐서 쉬는 시간을 잠으로 날리는 경우가 많았다.
그래도 다음주엔 무리하지 않고 7번의 쉬는 시간 중 딱 한 번이라도 복습을 하는 것을 목표로 수업을 들어야겠다.


NLTK Library를 이용하여 Text Processing을 위한 전처리 실습
(1) NLTK 불러오기
import nltk(2) 문장을 변수에 넣고 토큰화하기
토큰화는 단어 별로 쪼개는 것을 말한다.
text = "Hi. My name is CamelFilm. Nice to meet you. How are you today?"
nltk.word_tokenize(sentence)
(3) 품사 태킹하기
tokens = nltk.word_tokenize(text)
nltk.pos_tag(tokens)주요 품사 목록
N: Noun(명사)
V: Verb(동사)
J/A: Adjective(형용사) - 형용사는 두 개로 나눠진다고 한다.
(4) Stopwords 제거하기
from nltk.corpus import stopwords
stopWords = stopwords.words('english')
print(stopWords)영어에 등록된 불용어 찾아보기!
불용어란 아니不, 쓸用으로 실질적 의미를 가지고 있지 않은 단어를 의미한다.
우리말의 불용어로는 조사가 있으며 영어의 불용어로는 is, am, are, was, were, be 등이 있다.
stopwords에서는 우리말을 지원하지 않는다.
(5)문장에서 Stopwords 제거하기
modify = []
#불용어가 제거된 결과를 담기 위한 리스트
for token in tokens:
if token.lower() not in stopWords:
modify.append(token)
print(modify)
여기서 드는 궁금증!!

왜 token.lower()?? 소문자 변환 함수를 써줄까?
강사님 답변은 형태소 분석하고 쪼개고 품사 태깅하는 과정에서 영어기준으로는 강제로 다 소문자로 바꿔주기 때문이라고 했다. 사실 이 답변이 잘 납득되지 않는다. 그래서 혼자 소문자 변환 함수를 빼고 실행해봤더니


이런 결과가 떴다!
직접 코드로 봤는데도 잘 이해가 안되니 질문방에 질문을 남겨봐야겠다...
-불용어 사전과 관련지어 생각하기
-불용어 사전이 소문자만 담고있어서. 판단의 기준이 되는 애들을 다 소문자로 만듦.
-i 영문 쓸 때 보통 대문자인데 그것부터 소문자로 다 바꿈.
-모든 형태를 소문자로 바꿔서 체크
-불용어 사전에 맞춰서 형태소도 소문자로 바꿈
-번거롭게 대소문자 신경쓰면서 하지 않기 위해
(6)불용어 사전에 없는 단어 추가하기
불용어 사전에는 마침표와 콤마가 없으므로 추가해준다.
stop_words.append(',')
stop_words.append('.')
(7)Lemmatization
어근에 기반하여 기본 사전형인 Lemma를 찾는 것
lemmatizer = nltk.wordnet.WordNetLemmatizer()
print(lemmatizer.lemmatize("ate")실행결과> eat
(1) Stopwords준비하기
Stopwords에는 기본적으로 단어만 포함되어 있어 기타 특수문자는 따로 추가해야한다.
stop_words = stopwords.words("english")
stop_words.append(',')
stop_words.append('.')
stop_words.append('’')
stop_words.append('”')
stop_words.append('—')매번 이런식으로 특수문자를 포함하기는 것은 매우 귀찮은 일이다.
이럴 땐 정규표현식을 이용하면 된다.
(2) 정규 표현식(Regular Expression)이란?
정규 표현식은 특정한 규칙을 가진 문자열의 패턴을 표현하는 데 사용하는 표현식으로 텍스트에서 특정 문자열을 검색하거나 치환할 때 흔히 사용된다.
다양한 정규식 패턴 표현
| 패턴 | 설명 |
| ^ | 이 패턴으로 시작해야 함 |
| $ | 이 패턴으로 종료되어야 함 |
| [문자들] | 문자들 중에 하나이어야 함. 간으한 문자들의 집합을 정의함 |
| [^문자들] | [문자들]의 반대로 피해야 할 문자들의 집합을 정의함 |
| | | 두 패턴 중 하나이어야 함 (OR 기능) |
| ? | 앞 패턴이 없거나 하나이어야 함(Optional 패턴을 정의할 때 사용) |
| + | 앞 패턴이 하나 이상이어야 함 |
| * | 앞 패턴이 0개 이상이어야 함 |
| 패턴{n} | 앞 패턴이 n번 반복해서 나타나는 경우 |
| 패턴{n, m} | 앞 패턴이 최소 n번, 최대 m번 반복해서 나타나는 경우 (n 또는 m은 생략 가능) |
| \d | 숫자 0~9 |
| \s | 화이트 스페이스를 의미하는데, [\t\n\r\f]와 동일 |
| . | 뉴라인(\n)을 제외한 모든 문자를 의미 |



(3) 정규표현식 이용하여 토큰화 한 후 불용어 제거
import re #정규표현식 불러옴
stop_words = stopwords.words("english")
file = open('파일.txt', 'r', encoding="utf-8")
lines = file.readlines()
tokens = []
for line in lines:
tokenized = nltk.word_tokenize(line)
for token in tokenized:
if token.lower() not in stop_words:
if re.match('^[a-zA-Z]+', token):
tokens.append(token)(1) TF-IDF (Term Frequency - Inverse Document Frequency)
TF-IDF는 단어의 빈도와 역 문서 빈도를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다.
간단히 말해서 두 문서의 단어들을 수치행렬로 표현한 후 단어 빈도수를 계산하여 유사도를 확인하는 것이다.
-tf(d, t): 특정 문서 d에서의 특정 단어 t의 등장 횟수
-df(t): 특정 단어 t가 등장한 문서의 수
-idf(d, t): df(t)에 반비례하는 수
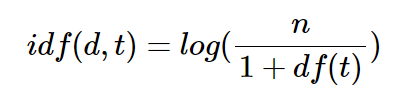
Q. 여기서 왜 분모에 1+를 해주나?
A. 분모가 0이되는 것을 방지하기 위함
log를 사용하여 that과 같이 자주 흔하게 꼭 쓰이는 단어들의 가중치가 커져 유사도를 잘못 계산하는 것을 방지한다.
예를 들어 'sky', 'green'처럼 문서의 고유성을 나타내는 단어들의 가중치를 더해 정확도를 높이기 위해 log를 사용한다.
(2) 코사인 유사도 (Cosine Similarity)
코사윤 유사도는 두 벡터간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다.


코사인 유사도에 대한 식은 위와 같다.
코사인 유사도를 이용하여 추천 시스템을 구현할 수 있다.
TF-IDF & Cosine similarity를 이용하여 텍스트 간 유사도 계산하기
(1) 패키지 불러오기
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity(2) 쪼개진 문자열들 하나로 합치는 코드
' '.join(['문자1', '문자2', '문자3'])(3) 텍스트 파일 불러오기
file = open('텍스트.txt', 'r', encoding='utf-8')
lines = file.readlines()
#텍스트 파일 불러와서 리스트로 만들어줌(4)TfidfVectorizer() 객체 변수 생성
vectorizer = TfidfVectorizer()(5) 텍스트 데이터 벡터화
먼저 fit_transform()을 통해 corpus의 텍스트 데이터를 벡터화 해 변수에 저장한다.
그 다음 해당 변수를 dense한 matrix로 변환한다.
X = vectorizer.fit_transform(corpus).todense()이 코드는 두 가지 코드가 합쳐졌다.
vectorizer.fit(corpus)
X = vectorizer.transform(corpus)(6) todense()
기본적으로 fit_transform으로는 희소행렬이 만들어지는데 이 행렬 안에는 무수히 많은 0이 존재한다.
그래서 0인 값들은 제외하고 나머지 숫자들만 저장하는 방식으로 처리한다.
결국 0도 메모리 공간을 차지하니까.
(7) 유사도 계산
with open('텍스트1.txt', 'r', encoding='utf-8) as f:
lines = f.readlines()
doc1 = ' '.join(lines)
with open('텍스트2.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
doc2 = ' '.join(lines)
corpus = [doc1, doc2]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus).todense()
print("두 텍스트 간의 유사도: ", cosine_similarity(X[1], x[2]))